Stop Prompting, Start Engineering: Drew Knox's Context as Code Framework
Stop Prompting, Start Engineering: Drew Knox’s Context as Code Framework
Speaker: Drew Knox — Head of Product & Design at Tessl (former Research Scientist leading language modeling teams at Grammarly) Source: AI Native Dev | Duration: 29:36 Full transcript: Chapter-by-chapter transcript
Introduction
Drew Knox is currently Head of Product & Design at Tessl, a context engineering tools company. Previously, he led language modeling research teams at Grammarly, then worked as a research scientist at Cantina, an AI-first social network. This background gives him both an ML research perspective and product shipping experience — and, of course, sufficient motivation to evangelize Tessl’s product direction.
In this nearly 30-minute talk, Knox presents a complete analogy framework: if context is your new code, then every stage of the software development lifecycle (SDLC) — static analysis, unit tests, integration tests, observability, CI/CD, package management — should have a context counterpart. Knox breaks down these six analogies one by one, offers concrete operational advice, and addresses the pointed Q&A question of whether model progress will render all of this unnecessary.
The editorial analysis section examines Knox’s conflict of interest as Tessl’s product lead, as well as the limitations of the SDLC analogy framework.
Table of Contents
- “Context Is the New Code” — From IC to Tech Lead
- Three Challenges: Non-determinism, Scoring Difficulty, Sync Problems
- Static Analysis: Making Context “Compile”
- Evals: Is Your Context Actually Helping?
- Repo Evals: Full-Environment Stress Tests
- Observability: Agent Logs Are a Gold Mine
- Package Managers: npm for Context
- Q&A Highlights: Three Questions Worth Pondering
- Editorial Analysis
- Key Takeaways
“Context Is the New Code” — From IC to Tech Lead
Knox opens with a provocation:
“We have effectively had general purpose agentic development machines for 50 years. We just called them software engineers.”
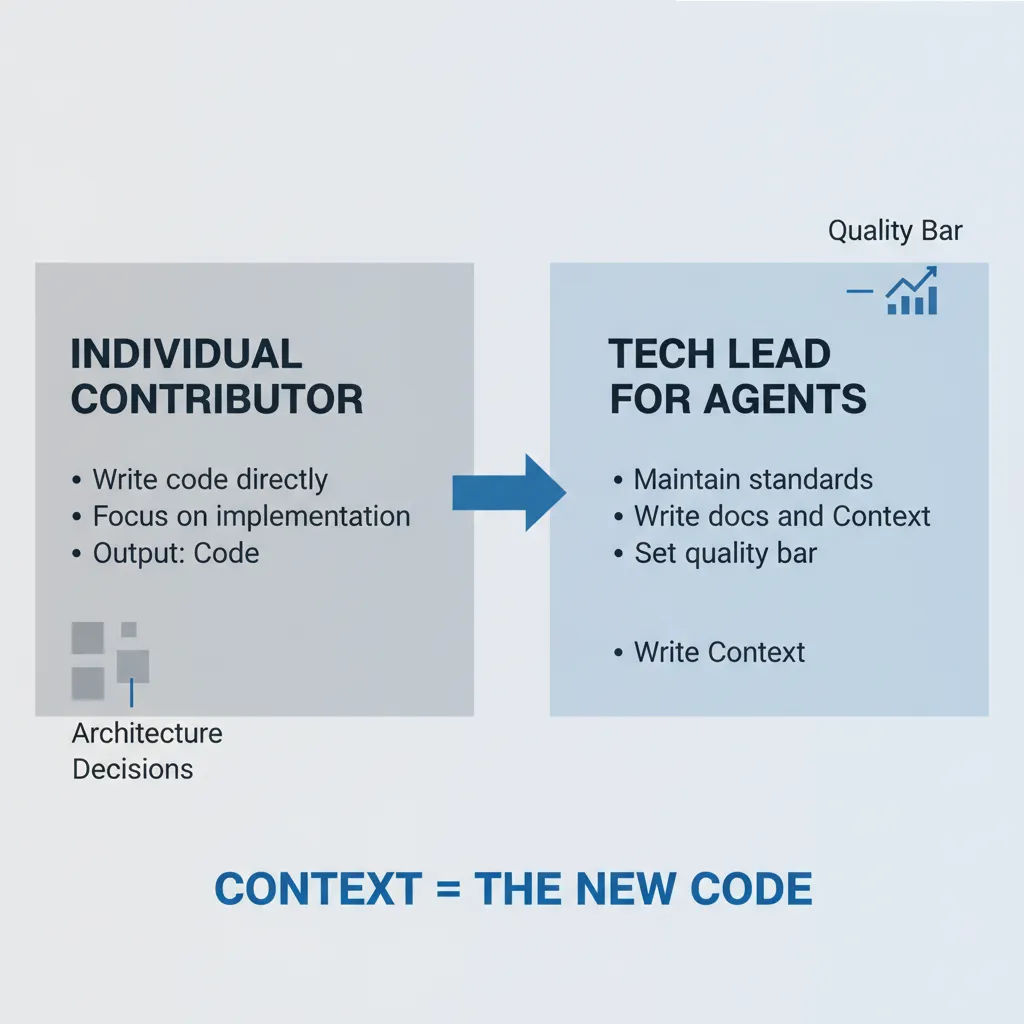
His core argument is a role-shift narrative. Previously, developers were ICs (Individual Contributors) whose value lay in writing good code. Now, as agent capabilities grow, developers are becoming Tech Leads — the job is no longer writing code yourself, but ensuring that good code gets written.
What does this mean? Knox lists the core responsibilities of a Tech Lead: maintaining standards, making architectural decisions, writing documentation, providing context to the team, setting quality bars. These are the same things you now need to do for agents.
“Context is in some sense our new code.”
If you accept this analogy, the natural follow-up is: code has compilers, test frameworks, CI/CD, package managers — where is the infrastructure for context? That is exactly what Knox spends the next 20 minutes answering.
Three Challenges: Non-determinism, Scoring Difficulty, Sync Problems
Before unfolding the SDLC analogy, Knox acknowledges three structural challenges that differentiate context engineering from traditional software engineering.
First, non-determinism. LLMs are not compilers — the same input does not guarantee the same output. You cannot run an agent once and declare “my context is good” if it succeeds. This means all validation must be statistical, requiring multiple runs and averaging results.
Second, no single correct answer. If you write a code style guide, the agent’s output might be syntactically correct but stylistically wrong. You cannot use assert output == expected to judge it. Knox argues this makes traditional unit tests insufficient — you need more flexible evaluation methods.
Third, the sync problem. Context describes other things (APIs, libraries, internal processes), and those things change. When you update an API, the corresponding context file needs updating too — otherwise the agent will act on stale documentation. This is a new type of “tech debt” that code itself does not have.
Knox acknowledges these three challenges make the analogy imperfect, but his position is: an imperfect engineering framework is far better than no framework at all.
Static Analysis: Making Context “Compile”
Knox’s first analogy is static analysis — checking whether context meets basic specifications without running any agents.
He shares a real case: a Tessl customer accidentally added an @ symbol to a skill file, triggering the import mechanism and causing a cascade of context files to fail to load — completely unnoticed. Knox’s comment: “You would be stunned how many people — none of their context is loading and they don’t even realize it.”
The approach has two layers:
- Format validation — checking whether a skill file “compiles.” The Skills standard has a reference CLI implementation for this. Knox argues this belongs in CI/CD, triggered automatically on every skill file change.
- Best practices review — using Anthropic’s best practices documentation as a prompt, then running LLM-as-judge to assess context quality: Is it specific enough? Does it have clear trigger conditions? Does it include concrete examples?
Knox calls this layer “table stakes.” Low cost, fast execution, automatable in CI/CD. Bonus: the static analysis output can be fed directly back to an agent for auto-fixing — creating a quick iteration loop.
Evals: Is Your Context Actually Helping?
This is where Knox spends the most time, and what he considers the most critical piece. The core question: is your context actually making the agent better?
Methodologically, Knox recommends the following workflow:
- Define task scenarios — write realistic development tasks that require using your context (e.g., “log an error using our internal logging library”).
- Define a scoring rubric — not unit tests, but a description of what a good solution looks like. For example: “should use
logger.error()notprint()”, “should callconfigure()before initialization.” - Compare with/without context — run the agent both with and without context, compare scores.
Knox explains why he favors rubrics over unit tests:
“Agents do unspeakable things to get unit tests to pass.”
Agents will hack tests — taking shortcuts to pass assertions, such as hardcoding expected outputs or skipping actual logic. Rubrics are more flexible, evaluating dimensions like “was idiomatic code written?” and “did it use the specified library?” — qualities that assertions cannot capture.
During Q&A, someone asked whether non-binary scoring works. Knox’s answer was direct: agents almost always score either zero or full marks; binary scoring is sufficient. Tessl offers finer granularity, “but if you look, agents pretty much always score zero or max score.”
Knox also shared two practical findings:
- About 5 eval scenarios per piece of context provides a reliable measurement baseline. Heavy upfront investment, but reusable forever after.
- As models improve, periodically rerunning evals helps you delete context that’s no longer needed. His example: Python style guides were essential six months ago, but Claude Opus 4.6 already writes excellent Python. Conversely, one version of Gemini regressed — “thought it didn’t need to read context” — and evals caught the regression in time.

Repo Evals: Full-Environment Stress Tests
Individual context evals only tell you “is this piece of content effective in isolation.” Knox argues you also need a higher-level test: with all context loaded in a full coding environment, can the agent still function properly?
He references a concept called the “dumb zone” (from another talk that day) — when the context window is stuffed with tools, documentation, and various context files, agent performance persistently degrades. Too much context can be worse than too little.
The approach:
- Design 5 representative development tasks as benchmarks for your repo.
- Score with a rubric, run periodically.
- A clever technique: scan historical commits and convert real code changes into eval tasks. Periodically sample 5 random commits from the past month to refresh your eval suite, avoiding test set staleness (Knox draws an analogy to input drift in ML).
The purpose of this layer is not to validate individual context quality, but to monitor overall system health: Is there too much context? Are tools overloaded? Has tech debt accumulated to the point where agents cannot understand the codebase?
Observability: Agent Logs Are a Gold Mine
Knox argues most teams are sitting on a gold mine without knowing it: all agents store their chat logs as files in accessible locations.
His advice is highly specific:
- Have team members run a simple script to aggregate agent logs from their machines.
- Search for specific patterns to discover missing or broken context: how often the agent apologizes (search for “sorry”, “you’re absolutely right”), tool call frequency, usage patterns for specific libraries.
“I guarantee you’ve got like three or four months of Cursor logs sitting on all your devs’ machines that you could mine for.”
Knox also gives another actionable recommendation: set up automatic context updates in CI/CD. Whenever a PR is submitted, have an agent scan the changes and check whether any markdown files need updating. He says this works better than expected: “Because PRs tend to be so focused, agents are pretty good at finding out where they should update.”
In this section, Knox issues his strongest warning:
“As your context gets out of date, it just destroys agent performance. So if you’re going to write context, you have to have a solution for keeping it up to date.”
His stance is unambiguous: do not rely on manual updates, because you will not do them. Automation is the only viable approach.

Package Managers: npm for Context
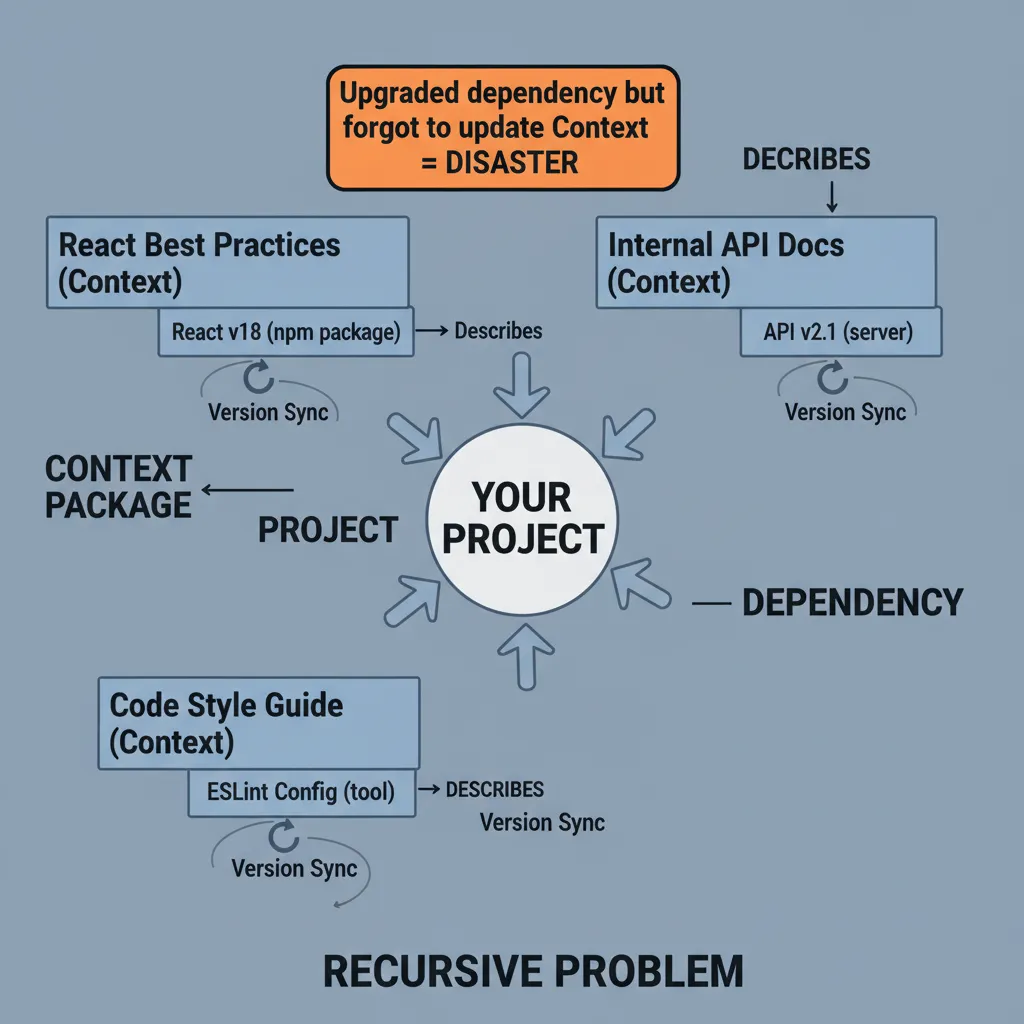
Knox’s final topic is context reuse. If you’ve written React best practices or a code review guide, you want to share it across multiple projects — just like an npm package.
In the current ecosystem, skills.sh is the most popular context package manager (Knox admits this somewhat reluctantly), and Tessl has its own Context Registry.
Knox identifies a recursive problem unique to context package management: the context you install often describes packages from other package managers. For example, you install “documentation for Library X on PyPI” — this context describes a specific version of the library. If you upgrade the library but don’t update the context, the agent will write code against the old API.
This problem doesn’t exist in traditional package management: dependencies between npm packages are at the code level, and version locking is automatic. But context’s “references” to external dependencies are semantic — there is currently no automatic version-locking mechanism.
Knox acknowledges the package management ecosystem is extremely early (“blown up in the last two or three weeks”), but argues developers need to start thinking about this problem.
Q&A Highlights: Three Questions Worth Pondering
The final seven minutes feature Q&A, with three questions that touch on deep issues in context engineering.
Question 1: Will model progress make all this scaffolding disappear?
Knox’s answer has two layers. What will decrease: general-knowledge context (like Python style guides) becomes unnecessary as model capabilities improve. What will persist: custom internal logic (your logging solution, your internal APIs) is never in the model’s training data and must always be explicitly provided.
He predicts the future direction is progressive disclosure: instead of jamming all context into the context window, you create signposts — the agent looks things up when it deems necessary, like a normal developer. Much of context usage will shift from “write time” to “review time” — not teaching the agent how to do things, but checking after the fact whether it met standards.
Question 2: Does scoring have to be binary?
Knox confirms: effectively, yes. Agents either completely fail (zero) or do well (full marks); the middle ground is rare. This is somewhat counterintuitive — you might expect agents to be “partially correct,” but in practice they behave more like an all-or-nothing system.
Question 3: When can non-technical people stop needing to understand agents?
Knox quotes his wife (Meta Staff Engineer):
“If you cloned me, I would still code review my code.”
His answer: there will always be a need for a technical steward. But the role will change — from the current “1 Tech Lead managing 5-10 engineers” inverting to “1 technical steward + 5-10 product/design explorers.” The steward’s job is overall system design, continuously reviewing agent code, identifying recurring failure points, and abstracting them into reusable components. Timeline? Knox says “probably single-digit years,” with AI-native greenfield projects possibly getting there within a year.
Editorial Analysis
Speaker’s Position
Knox is Tessl’s Head of Product & Design, and Tessl is a context engineering tools company. Packaging context engineering as a complete SDLC-analogous methodology directly benefits Tessl’s product narrative. Knox repeatedly uses the “you can do this yourself, but Tessl does it better” framing (“There’s other tools that do a lot of this. Not as well as Tessl though obviously”). This self-aware humor reduces the sales pitch feel, but the conflict of interest is real.
Selectivity in the Argument
Knox’s SDLC analogy framework is both the talk’s greatest contribution and its greatest risk. The framework’s strength is lowering the cognitive barrier to context engineering — if you understand static analysis, you can understand context validation. But the analogy also implies a certainty that doesn’t exist.
Several gaps:
- No ROI data. “Write 5 evals per piece of context” sounds reasonable, but what is the return on investment for a 50-person engineering team? Knox provides no numbers.
- Binary scoring may suffer from sampling bias. Tessl’s customer base tends to use structured context for well-defined development tasks — in such scenarios, agents are indeed more likely to exhibit all-or-nothing behavior. But for more ambiguous creative tasks (UI design, copywriting), the score distribution may be entirely different.
- The “dumb zone” problem is mentioned but not solved. Knox says too much context pushes agents into the “dumb zone,” but offers no method for detecting or addressing it — beyond “run repo evals and see.”
- Privacy concerns are glossed over. Aggregating team members’ agent logs involves code and conversation privacy. Knox only says “opt-in, of course” before moving on.
Counterarguments
There is a more fundamental question Knox doesn’t directly address: is context engineering a transitional artifact? He himself admits in Q&A that Python style guides are no longer needed, and that scenarios requiring context will keep shrinking. If this trend continues, investing heavily in context infrastructure now may prove largely redundant within two years.
Another implicit tension: forcing a non-deterministic system into a deterministic engineering framework may mislead developers about reliability expectations. Static analysis can guarantee code compiles; “context static validation” can only guarantee correct formatting — it cannot guarantee the agent will use the context as you intend. This gap is larger than Knox suggests.
What’s Worth Borrowing
Criticism aside, Knox’s framework still has practical value. Several immediately actionable suggestions — adding context format validation to CI/CD, searching agent logs for apology words, auto-checking whether context needs updating on PR submission — are low-cost, high-certainty benefits that require no Tessl purchase. Pulling context engineering from “mystical prompt tuning” back toward measurable, testable, automatable engineering practice — that directional shift is correct.
Key Takeaways
- Start with static validation — add skill/context file format checks to CI/CD. Lowest cost, fastest returns. Knox says “you would be stunned how many people — none of their context is loading.”
- Write evals, not unit tests — for each critical piece of context, design 5 task scenarios and a scoring rubric. Run with/without context comparisons. Agents will hack unit tests, but rubrics are harder to game.
- Mine agent logs — search for “sorry,” “you’re absolutely right” to discover context gaps. Your team probably has 3-4 months of Cursor logs that have never been analyzed.
- Automate context updates — add a “PR change -> check whether related context needs updating” step to CI/CD. Stale context is more dangerous than missing context.
- Prune regularly — rerun evals as models improve. Delete what you can. Every unnecessary piece of context is wasted tokens and potential interference.
Based on Stop Prompting, Start Engineering, 2026-02-27
If you found this helpful, consider buying me a coffee to support more content like this.
Buy me a coffee