Google Didn't Build Gemini 3 to Chat - It Built It for World Models
Source: This article is reposted from SETI Park (@seti_park)’s X Article, originally published on February 22, 2026.
About the author: SETI Park is a Korea-based Patent Analyst who specializes in deep technical analysis of patents from major tech companies including Tesla, NVIDIA, Google/DeepMind, SpaceX, and Anthropic. He distills strategic insights from patent filings and has over 16,000 followers on X. He also runs a YouTube channel.
TLDR: Google’s patent US20260030905A1 reveals the true purpose behind Gemini 3’s vision capabilities — not chat, but building World Models. The patent describes a ConGen-Feedback system that detects four types of image-text misalignment (object, attribute, action, spatial relation), improves through iterative self-correction loops, and manufactures training data at scale. These four dimensions are exactly what’s needed to simulate physical reality, and Gemini 3’s benchmark results map perfectly onto them. From the 2023 SeeTRUE paper to 2026’s Waymo World Model, Google has been following the same roadmap all along.

On February 6, Waymo unveiled the Waymo World Model, a simulation engine for autonomous driving built on Google DeepMind’s Genie 3. It generates driving scenarios the fleet has never encountered: tornadoes, flooded intersections, elephants on the road. The blog post noted that “Genie 3’s strong world knowledge from diverse video pre-training enables our vehicles to explore scenarios never directly observed by the fleet.”
That phrase, world knowledge from video pre-training, connects to a question the tech press has mostly ignored:
Why has Google invested so heavily in compositional vision: the kind that understands objects, attributes, actions, and spatial relations, not just “sees” an image?
The numbers tell part of the story. Google’s own benchmark table for Gemini 3 Pro spans 25+ evaluations across seven vision categories. It leads in every single one. But benchmarks are outputs. They tell you what the model can do, not why it was built that way.
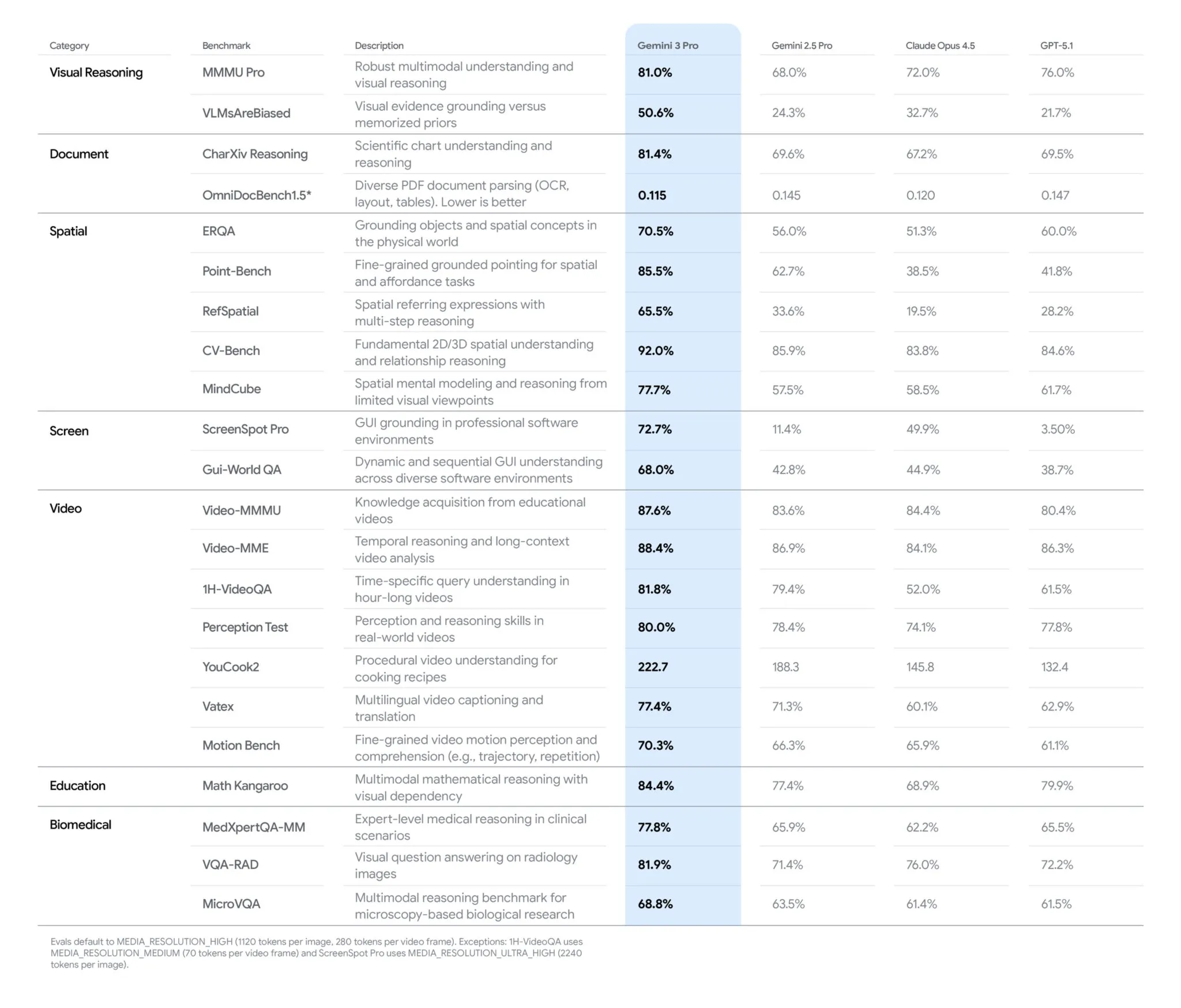
Look at what Google chose to measure. “Spatial” is a standalone category with five dedicated benchmarks. “Screen” has three. These aren’t generic accuracy tests. They’re measuring the specific capabilities a physical world model requires.
A patent, US20260030905A1, filed May 2024, published January 29, 2026 suggests the roadmap is architectural, not incremental.
A system that doesn’t just score image-text alignment. It explains where and why they disagree, corrects them iteratively, and generates training data for each type of misalignment at scale.
The thesis: Gemini 3’s strength in compositional vision is the output of a recursive self-correction engine, designed not for chat but for building world models.
Not Scores, But Explanations
Existing metrics like CLIPScore produce a single number. 0.7 means “probably aligned.” But they never tell you where the misalignment is, or why. The patent is blunt: embedding-based models like CLIP “often struggle with tasks requiring fine-grained compositional understanding” [0005]. Textual similarity metrics “only assess textual similarity, ignoring visual information and deeper semantic connections” [0035].
The patent proposes ConGen-Feedback: a system that outputs both a textual explanation and a bounding box annotation of what went wrong.
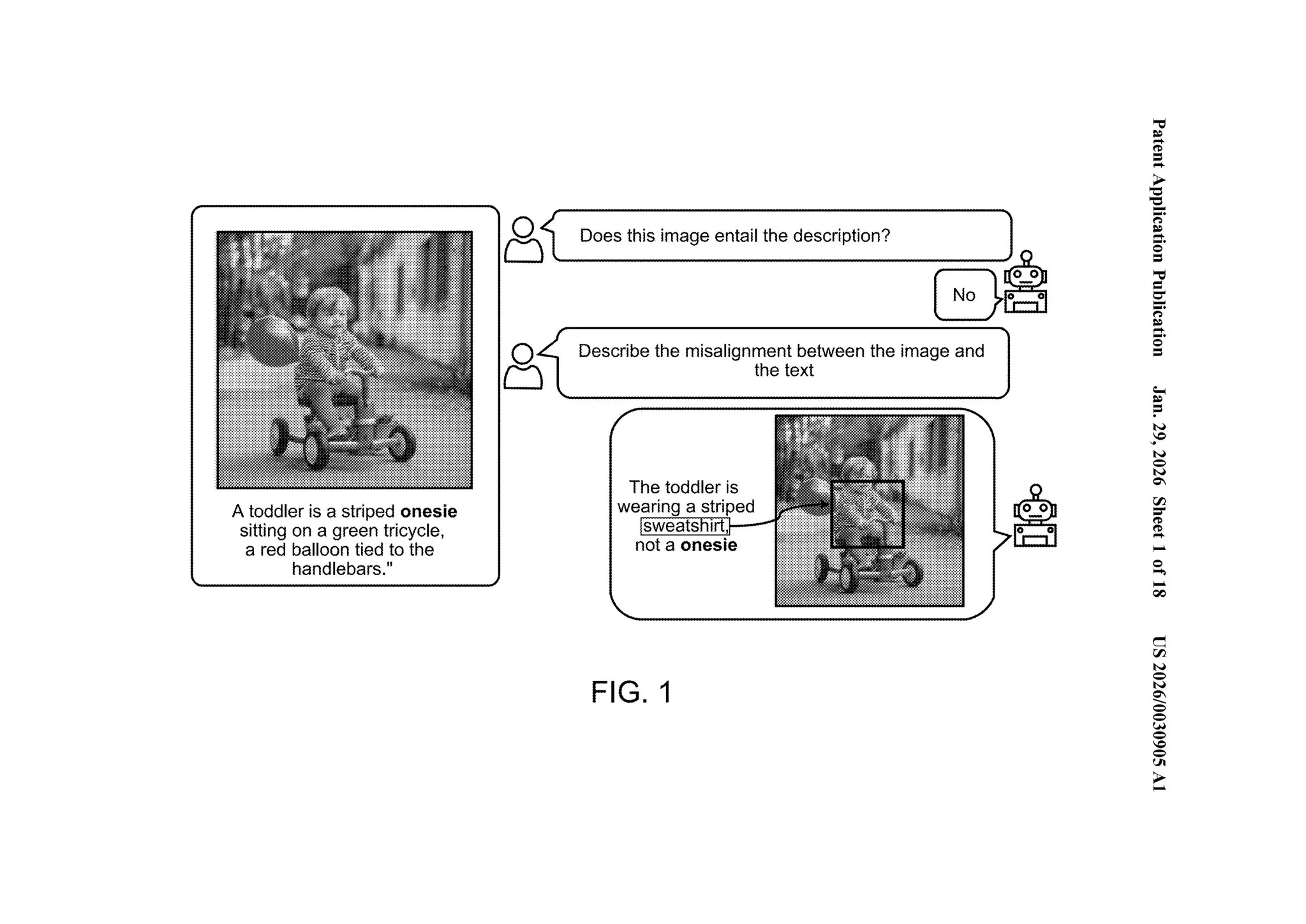
FIG. 1 makes this concrete. The text describes “a toddler in a striped onesie sitting on a green tricycle.” The image shows the same toddler wearing a striped sweatshirt. The system detects this, generates the textual explanation, and draws a bounding box around the clothing [0066].
One model, two outputs: what’s wrong (text) and where it’s wrong (vision).
“By employing a single machine-learned model to produce both textual and visual descriptions of misalignments, the system avoids the duplication of computations… improving memory usage and decreasing inference time.” — [0061]
The academic foundation, the SeeTRUE paper (NeurIPS 2023) by the same Google Research Israel team, states that such models may be useful for “filtering training data [to] improve training of text-to-image models.”
This isn’t an evaluation tool. It’s infrastructure for vision models to learn from their own mistakes.
The Correction Loop
The detection process repeats. The system generates a textual diagnosis, then processes it through a second model that modifies the image (or text). The modified output goes back through the same detection system.
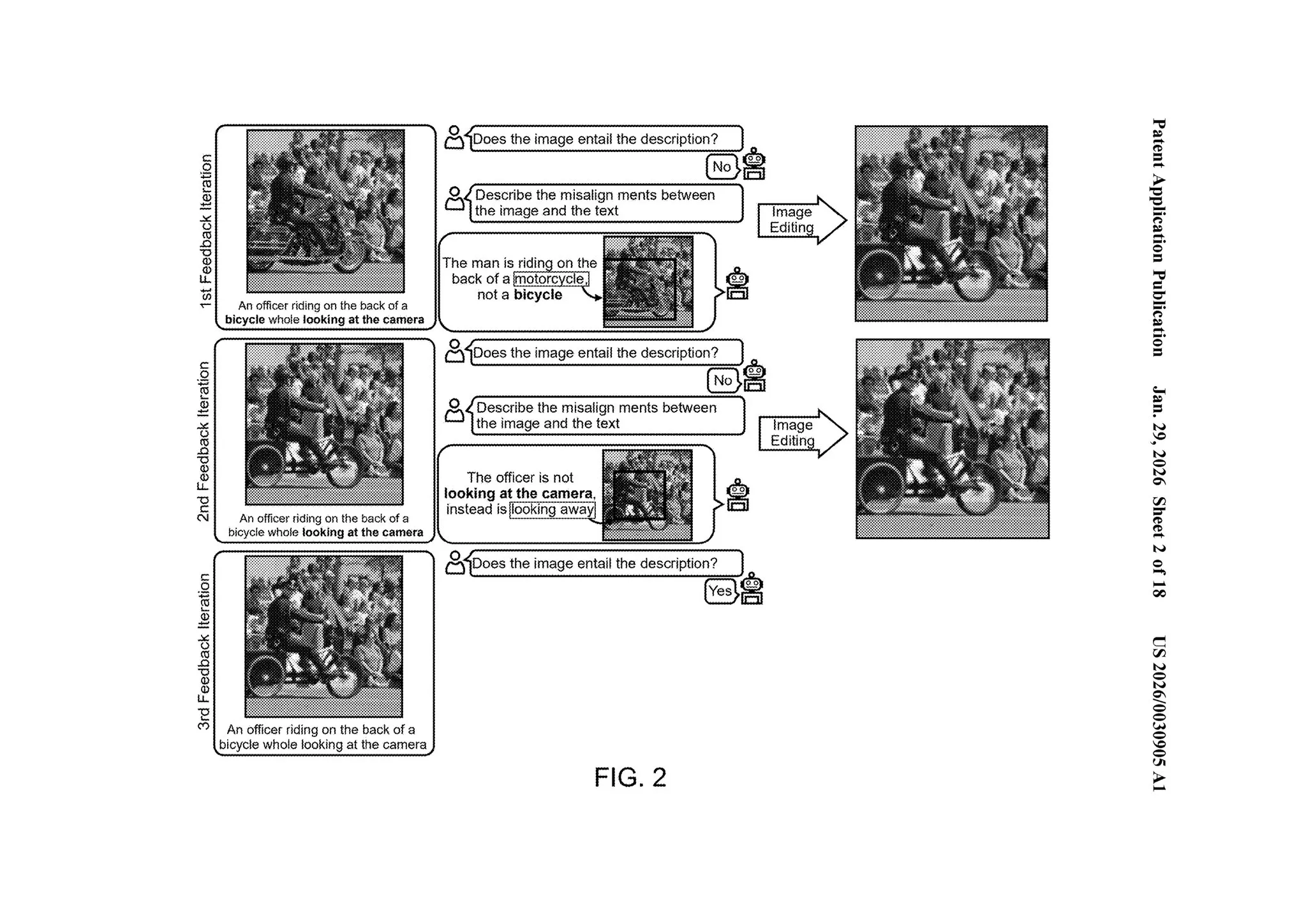
FIG. 2 shows the full cycle.
Text: “an officer riding on the back of a bicycle while looking at the camera.”
Iteration 1. “No. The man is riding on the back of a motorcycle, not a bicycle.” Bounding box on the motorcycle. Image is regenerated with a bicycle.
Iteration 2. “No. The officer is not looking at the camera, instead is looking away.” Bounding box on the face. Image is regenerated with the officer facing the camera.
Iteration 3. “Yes.” Image now matches the description.
The patent describes handling multiple simultaneous discrepancies: “the source text string might describe an image having a blue house, but the generated image may include a red house. Or a source text string may describe a scene involving a cat, but the generated image may include a dog instead.” [0004]
This is an iterative reward-and-correction cycle. The model doesn’t just identify failure modes, it fixes them and re-checks. Each cycle adds to the training data.
Four Misalignments = The Grammar of Physical Reality
The misalignment taxonomy isn’t arbitrary. The patent defines four categories [0045]:
Object. “Cat” vs. dog. Right scene, wrong entity.
Attribute. “Blue cat” vs. white cat. Right object, wrong properties.
Action. “Jumping” vs. standing. Right object and attributes, wrong behavior.
Spatial relation. “Jumping over a fence” vs. jumping next to it. Everything correct except relative positions.
These four dimensions, what exists, what it looks like, what it’s doing, where it is, are exactly what a world model needs to simulate physical reality. And Google’s benchmark suite maps directly onto them.
MMMU-Pro (81%) tests whether the model can reason about object attributes and relationships in complex visual scenes. Video-MMMU (87.6%) tests whether it tracks actions and state changes over time. And the Spatial category, five benchmarks deep, tests exactly what the patent’s fourth misalignment type demands: RefSpatial measures multi-step spatial reasoning (65.5%, nearly double Gemini 2.5 Pro’s 33.6%). MindCube measures spatial mental modeling from limited viewpoints (77.7% vs. GPT-5.1’s 61.7%).
The patent trains the model to detect four types of physical misalignment. Google built a benchmark suite to measure exactly those four dimensions. The results speak for themselves.
The Training Data Factory
The patent manufactures these misalignments at scale via the TV-Feedback pipeline. For each aligned image-text pair, it generates negatives across all four categories. A positive caption like “a cat lying on a blue mat” produces variants: “a dog lying on a blue mat” (object), “a cat lying on a red mat” (attribute), “a cat sitting on a blue mat” (action), “a cat lying under a blue mat” (spatial).
An NLI model filters quality: samples with contradiction correctness (CC) above 0.25 and samples with a minimum entailment precision. The system retains only mismatches that are hard enough to be useful.

FIG. 3 shows the result: training pairs across six datasets (PickaPic, ImageReward, COCO, Flickr30k, DOCCI, SVO-Probes) with explanations and bounding boxes for each misalignment type.
A factory for producing “wrong versions” of physical reality at unlimited scale, and teaching the model to detect and correct them.
The patent also introduces VQ², a scoring method that decomposes alignment into atomic question-answer pairs. Rather than a single score, the system generates 10-20 binary questions about specific aspects of the image (“Is there a cat?”, “Is the mat blue?”, “Is the cat lying down?”), reducing hallucination and enabling fine-grained debugging.
The patent names its target models explicitly: “Example VLMs include the PaLI and Gemini model families” [0036]. Not a specific version. The model families.
The Timeline
2023. SeeTRUE (NeurIPS 2023) establishes image-text alignment evaluation by the Google Research Israel team.
2024. The same team publishes ConGen-Feedback (ECCV 2024), proposing the recursive self-correction system. Google files the patent (priority date May 17, 2024), covering the detection system, synthetic data pipeline, iterative correction loop, and VQ² scoring methodology.
2025, May. At Google I/O, Demis Hassabis announces: “We’re extending Gemini to become a world model that can make plans and imagine new experiences by simulating aspects of the world.”
2025, August. Genie 3 launches. DeepMind calls it “a new frontier for world models.” Researchers state: “We think world models are key on the path to AGI, specifically for embodied agents.”
2025, November. Gemini 3 Pro debuts. Google publishes a benchmark table with seven vision categories and 25+ evaluations, sweeping all of them. The largest gaps over competitors appear in Spatial and Screen, the categories most dependent on compositional reasoning.
2026, January. Google ships Agentic Vision in Gemini 3 Flash: a Think-Act-Observe loop where the model plans a visual analysis strategy, manipulates the image (zoom, crop, enhance), then re-examines the result. The structure, detect → manipulate → re-detect, mirrors the patent’s iterative correction cycle. Same month, the patent is published.
2026, February. Waymo World Model launches on Genie 3, converting 2D video understanding into multi-sensor 3D output for autonomous driving simulation. The system generates scenarios “never directly observed by the fleet.”
What the Patent Reveals
Every AI company is improving vision accuracy. This patent reveals something different: infrastructure for recursive self-improvement. A system that detects where and why misalignments occur, generates unlimited training data across four dimensions of physical understanding, then uses iterative correction to feed better models.
Gemini 3’s compositional vision strength isn’t the destination. It’s a checkpoint on the way to AI that can model, predict, and simulate the physical world.
The patent trail suggests it’s been the plan all along.
Sources
- US 2026/0030905 A1, “Vision-Language-Model-Based System for Assessing the Consistency Between Images and Textual Descriptions,” filed May 2024, published January 29, 2026
- Yarom et al., “What You See is What You Read? Improving Text-Image Alignment Evaluation,” NeurIPS 2023
- Bitan et al., “Mismatch Quest: Visual and Textual Feedback for Image-Text Misalignment,” ECCV 2024
- Google, “Gemini 3 Pro: the frontier of vision AI,” Google Blog, 2025
- Hassabis, “Google I/O 2025: Gemini as a universal AI assistant,” Google Blog, May 20, 2025
- Google DeepMind, “Genie 3: A new frontier for world models,” August 5, 2025
- Waymo Blog, “The Waymo World Model,” February 6, 2026
If you found this helpful, consider buying me a coffee to support more content like this.
Buy me a coffee