Ilya Sutskever: The Age of Scaling Is Over
Guest Profile
Ilya Sutskever, founder and CEO of SSI (Safe Superintelligence Inc.). Co-inventor of AlexNet (2012), co-founder and former Chief Scientist of OpenAI (2015-2024), co-author of the GPT series of papers. Founded SSI in 2024, raising a cumulative $3 billion at a $32 billion valuation.
Source: Dwarkesh Podcast, published November 25, 2025, 96 minutes.
Background: This is Ilya’s most in-depth public conversation since leaving OpenAI. In November 2023, he participated in the OpenAI board’s attempt to oust Sam Altman. He formally departed in May 2024 and founded SSI. After co-founder Daniel Gross was recruited by Meta in July 2025, Ilya assumed the role of CEO himself.
This nearly two-hour conversation covers the most critical fault lines in the AI industry today: the disconnect between model benchmarks and economic returns, the ceiling of the scaling paradigm, the mystery of human learning efficiency, and the role of emotions in intelligence. Ilya’s judgment – “there are far more companies than ideas” – points to a truth Silicon Valley would rather not face: when everyone is doing the same thing, genuine innovation stalls. He is reconsidering the “rush to superintelligence” approach and reveals that SSI’s technical direction involves a fundamental question he “has strong opinions about but circumstances prevent discussing publicly.” When discussing the ultimate goal of AI, he argues that superintelligence should care for “sentient life” rather than just humans – because in the future, humans will comprise only a tiny fraction of sentient beings.
Chapter 1: A Puzzling Disconnect – Eval Performance vs. Economic Impact
Ilya opens with a counterintuitive observation: there is a severe mismatch between current AI models’ benchmark scores and their economic impact.
“The models seem smarter than their economic impact would imply. This is one of the very confusing things about the models right now.”
This disconnect manifests in daily use. Ilya gives a coding assistance example: you tell the model about a bug, it fixes it but introduces a second bug; you point out the second bug, and it brings the first one back. The two bugs can alternate endlessly. How can a model that performs brilliantly on evals make this kind of mistake?
He offers two explanations. The first he calls “whimsical”: RL training may have made models too narrow and singular, gaining certain capabilities while losing basic holistic awareness. But the second explanation carries more structural significance.
The pre-training era had one enormous advantage: no need to choose data. All data was fed in, and results emerged naturally. But when the industry shifted to RL training, choice became unavoidable – which environments to train in, which objectives to optimize, all requiring human decisions. In making these decisions, researchers unconsciously designed RL environments around eval benchmarks. They look at leaderboards and think: I want the model to excel at this task, so I’ll design training environments for it.
Ilya makes this more vivid with an analogy: the 10,000-hour student vs. the gifted student. One student practices 10,000 hours to become the best competitive programmer, memorizing every algorithm template and proof technique; another student practices only 100 hours but performs equally well. Who will be more successful in their future career? The answer is obvious. Current RL training is essentially producing the first type of student – achieving high scores through massive targeted training, but these capabilities may not transfer to other settings.
“The real reward hacking is the human researchers who are too focused on the evals.”
Academic evidence supports this assessment. The Stanford HAI 2025 AI Index Report notes that traditional benchmarks like MMLU and GSM8K are approaching saturation, forcing researchers to continually create harder new benchmarks. An ACL 2025 paper, “Data Laundering,” directly demonstrated benchmark gaming techniques – a mere 2-layer BERT model achieved 73.94% on GPQA through knowledge distillation, close to OpenAI o1’s 77.3%. When a tiny model can approach the eval scores of frontier systems, what do those scores even mean?
This isn’t one team’s problem – it’s the result of structural industry incentives. When funding, valuations, and media coverage all revolve around eval scores, the entire system is doing the same thing: making numbers look good.
Chapter 2: From 2020 to 2025 – Scaling Ate All the Oxygen

Ilya divides the past decade-plus into two eras. 2012 to 2020 was the Age of Research: people tried various ideas, searching for interesting results. 2020 to 2025 was the Age of Scaling: scaling laws and GPT-3 made everyone realize they “should scale.”
He believes the power of the word “Scaling” itself is underestimated.
“From 2012 to 2020 it was the age of research. From 2020 to 2025 it was the age of scaling. But now the scale is so big… it’s back to the age of research again, just with big computers.”
Scaling is one word, but it told everyone what to do. Companies especially loved this paradigm because it provided a low-risk resource allocation method – no need for researchers to take risks exploring unknown directions, just “get more data, more compute,” and improvement was guaranteed. By comparison, investing in research is far riskier: you send out researchers to explore, and they might find nothing.
The greatness of pre-training was that it was a known recipe: combine a certain amount of compute, data, and a certain scale of neural network, and results would be better – and you knew it would be better. But data is finite. Ilya puts it bluntly: “Pre-training will eventually run out of data. Data is obviously finite. Then what do you do?”
Compute is already massive. He presses a key judgment: if you scale current levels by 100x, will everything fundamentally change? “There’ll be improvement, but I don’t think it’ll bring a qualitative leap.”
This judgment is far from consensus in the industry. Geoffrey Hinton believes scaling is far from over and that AI will generate its own training data to break through bottlenecks. Dario Amodei has stated “scaling alone will get us to AGI.” Demis Hassabis insists we “must push scaling to the maximum,” giving AGI a 50% probability of arriving by 2030. Sam Altman continues pouring tens of billions into infrastructure. Only Yann LeCun partially agrees with Ilya, calling “general intelligence complete BS.”
Another consequence of the scaling era is the homogenization of ideas. Scaling sucked all the oxygen out of the room, and everyone started doing the same thing.
“We are in a world where there are more companies than ideas by quite a bit… If ideas are so cheap, how come no one’s having any ideas?”
Silicon Valley has an old saying: ideas are cheap, execution is everything. Ilya agrees this has merit, but it masks a fact – when execution becomes the same thing everyone is doing, what’s truly scarce is differentiated thinking. He looks back at history: AlexNet used only 2 GPUs, and the Transformer paper used no more than 64 GPUs from 2017 (equivalent to about 2 modern GPUs). Breakthrough research has never required maximum-scale compute.
Chapter 3: Why AI Generalizes Worse Than Humans – A Fundamental Gap
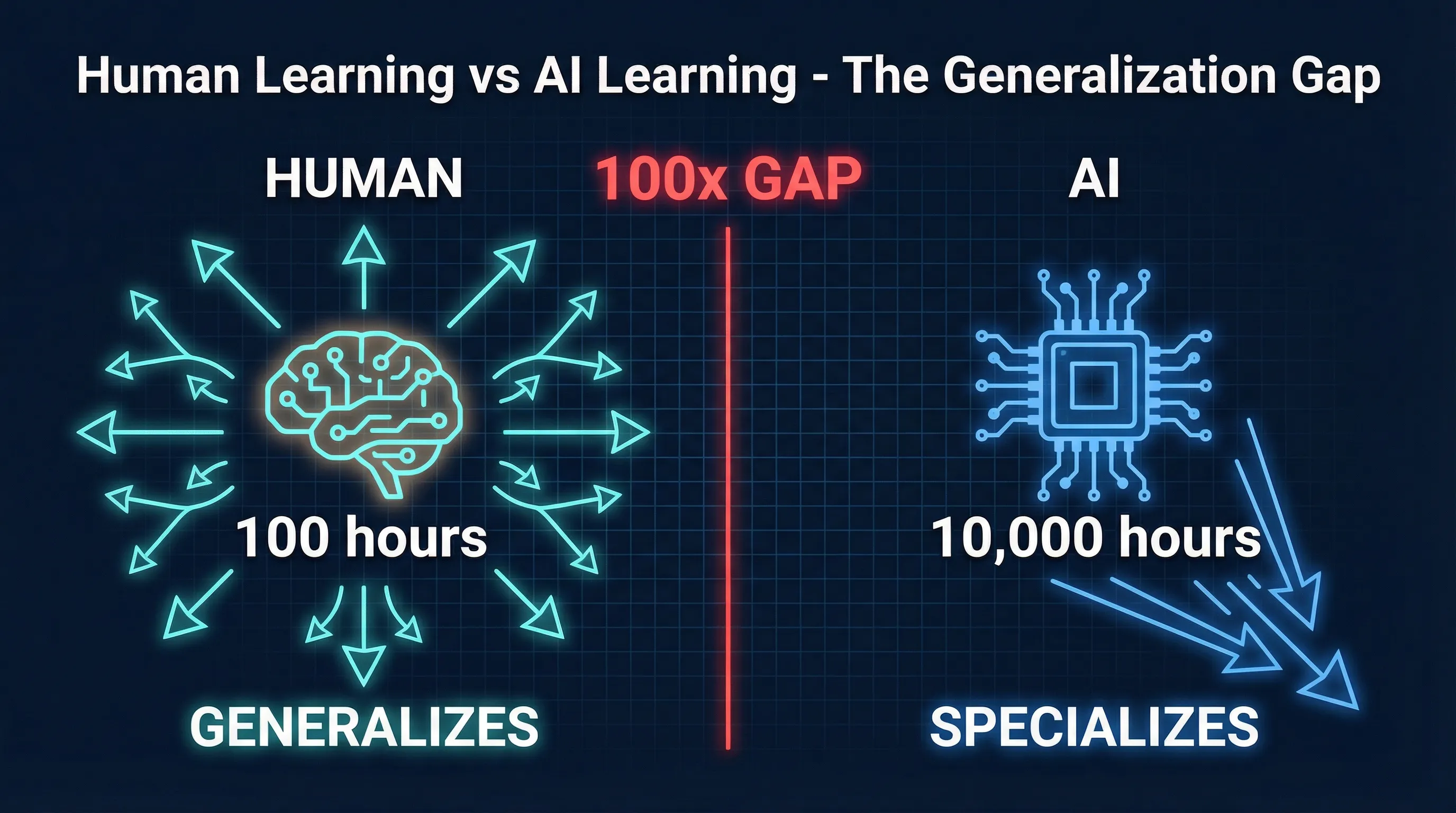
In Ilya’s analytical framework, the disconnect between evals and economic impact, and the ceiling of scaling, ultimately point to the same fundamental problem: generalization.
“These models somehow just generalize dramatically worse than people. And it’s super obvious that seems like a very fundamental thing.”
He breaks the generalization problem into two sub-problems. First is sample efficiency – why do models need far more data than humans to learn the same thing? Second is teachability – why is teaching a model something so much harder than teaching a human? When mentoring a young researcher, you don’t need to set up a verifiable reward function, design a curriculum, or worry about training instability. You show them your code, share your thinking process, and they learn your research methodology from it. Models can’t do this.
For sample efficiency, a natural explanation is evolution. Evolution gave humans the minimal amount of the most useful information. In vision, hearing, and motor skills, this explanation holds – human flexibility far exceeds robots, and robots need extensive simulation training to approach human-level performance. You could say these are prior knowledge accumulated through hundreds of millions of years of ancestral evolution.
But Ilya points to a crucial exception: math and programming. These are recently invented skills that evolution never prepared us for. Yet humans still demonstrate far greater efficiency and robustness than models when learning math and programming. This means the human learning advantage comes not just from evolution’s hardcoded priors, but from some more fundamental learning principle.
When host Dwarkesh Patel presses for what this principle specifically is, Ilya gives a suggestive answer:
“That is a great question to ask, and it’s a question I have a lot of opinions about. But unfortunately, circumstances make it hard to discuss.”
He adds a factor that could make the problem harder: human neurons may perform more computation than we think. If this is a key factor, replicating human learning capability becomes even more difficult. But regardless, he believes the existence of humans itself proves this learning principle is achievable.
This part of the conversation deserves careful consideration. From an analytical standpoint, this is an unfalsifiable claim – he claims to possess key insights but cannot share them publicly, leaving readers unable to evaluate their truth. This could be an honest expression that SSI has indeed identified a unique technical direction, or it could be strategic ambiguity providing narrative support for a zero-revenue, pure-research company’s $32 billion valuation. EA Forum analyst Yarrow Bouchard noted that SSI’s secrecy “conveniently masks the fact that they might not have any brilliant ideas that OpenAI and DeepMind don’t also have.” Historically, AI startups focused on fundamental research – such as Vicarious and Numenta – have failed to productize their research.
But we must also acknowledge: Ilya is one of the very few people who has been present at and driven every key inflection point in deep learning. His judgment has been repeatedly validated over the past decade. When such a person says “there exists an unknown fundamental learning principle,” even if it can’t be verified, it deserves serious attention.
Chapter 4: Emotions Are Not a Bug, They’re a Feature – Value Functions and the Secret of Human Decision-Making

When discussing the roots of human learning efficiency, Ilya introduces a surprising angle: emotions.
He mentions a neuroscience case. A person lost their emotional processing ability due to brain damage – no longer feeling sadness, anger, or excitement. Intelligence tests showed everything was normal; he could still solve puzzles. But in daily life, he completely fell apart.
“He stopped feeling any emotion… and he became somehow extremely bad at making any decisions at all. It would take him hours to decide which socks to wear.”
This case most likely corresponds to patient “Elliot” documented by neuroscientist Antonio Damasio – ventromedial prefrontal cortex damage, intact intelligence but severely degraded decision-making ability. Damasio’s Somatic Marker Hypothesis proposes that emotions are not interference in rational decision-making, but a necessary component of it. Without emotional signals as “markers,” humans cannot make effective decisions in the real world even with fully intact reasoning abilities.
From this, Ilya draws an analogy critical to AI training: the core bottleneck of current RL is that it provides only terminal rewards. A model receives a problem, goes through thousands or even hundreds of thousands of reasoning steps to produce an answer, and only then receives a score as a training signal. Before the answer emerges, no learning occurs throughout the entire process. This is how O1, R1, and similar systems work.
The value function serves to “short-circuit” this long wait. Take chess as an example: if you lose a piece, you don’t need to finish the entire game to know something went wrong. The value function lets you judge whether the current direction is good during the process, dramatically accelerating learning.
Humans naturally possess this mechanism. A teenager learning to drive can be on the road in 10 hours. Not because they received some carefully designed verifiable reward, but because they have a built-in value function – an immediate, intuitive feedback system telling them “this doesn’t feel right” or “getting the hang of it.”
Even more striking is this system’s robustness. The human emotional value function was designed during evolution for a completely different environment – survival challenges on the African savanna – yet it remains largely effective in modern society.
“Whatever the human value function is, with a few exceptions around addiction, it’s actually very, very robust.”
Ilya believes this robustness comes precisely from the simplicity of emotions. Complex systems may be useful in specific scenarios, but simple systems are useful across an extremely wide range of situations. The human emotional system was mostly inherited from mammalian ancestors, with only minor fine-tuning during the human phase, adding some social emotions. Because it’s not overly complex, it remains applicable in a modern world radically different from its original environment.
But this leads to a deeper mystery. Ilya says understanding how evolution encodes low-level desires (like preferences for food smells) isn’t difficult – smells are chemical signals, and evolution just needs the brain to chase certain chemicals. But evolution also gave humans complex high-level social desires: we care about others’ opinions, about social status, about our standing within groups. These aren’t low-level sensory signals – the brain needs to integrate vast amounts of information to understand “social situations,” and then evolution says “this is what you should care about.”
He believes these social desires are products of recent evolution, demonstrating that evolution is extremely efficient at encoding high-level desires. But as for the specific mechanism, he admits he has no satisfactory hypothesis. He once proposed a conjecture – perhaps evolution hardcodes desires through “GPS coordinates” of brain regions, where activation of a fixed-location brain area triggers the corresponding desire. But he himself rejected this conjecture: some people had half their brain removed in childhood, and all brain functions reorganized into the remaining hemisphere. Brain region locations are not fixed.
This mystery has direct implications for AI alignment. If we cannot understand how evolution encoded desires – which require the brain’s full high-level computation to even comprehend – in an “unintelligent” genome, then engineering similar mechanisms in AI systems may be far more difficult than expected. Ilya doesn’t provide an answer, but he outlines the problem clearly enough: the success of the human emotional system is a biological clue for alignment, and we are far from understanding the principle behind this clue.
Chapter 5: “Humans Are Not AGI” – Continual Learning and the True Form of Superintelligence
In the interview, Ilya conducts a seemingly simple but profoundly consequential piece of linguistic archaeology.
Why does the term AGI exist? It’s not a precise description of the end state of intelligence, but a reactive artifact. Early game AI and chess AI were uniformly labeled as “Narrow AI” – could beat Kasparov at chess but couldn’t do anything else. In response, some people proposed the concept of “Artificial General Intelligence”: no longer narrow, but capable of everything.
The pre-training paradigm further reinforced this concept. Pre-training’s characteristic was exactly this: invest more data and compute, and the model gets better at all tasks – “almost uniformly.” More pre-training equals more general, more general means AGI. Concept and technical roadmap aligned perfectly.
But Ilya believes this narrative “overshot the target.”
“A human being is not an AGI. A human being lacks a huge amount of knowledge. Instead, we rely on continual learning.”
What is the true state of a human being? A 15-year-old possesses extremely strong learning ability and basic skills, but knows almost nothing about the world. They’re not a “finished product” but a learning system.
Ilya uses this analogy to describe his vision of superintelligence:
“I produce a super intelligent 15 year old that’s very eager to go… You go and be a programmer, you go and be a doctor, go and learn.”
This redefines the meaning of “deployment.” Deploying superintelligence isn’t releasing a finished product to market – it’s the beginning of a learning process. AI would join an organization like a human worker – first learning, then getting hands-on, gradually accumulating experience.
This leads to a deeper implication. If multiple instances of a model are simultaneously deployed across different economic sectors – one learning programming, one learning medicine, one learning law – the knowledge each accumulates can be merged. This is something humans cannot do. Humans can’t “merge brains,” but AI can.
Ilya argues that even without recursive self-improvement, through this mechanism of multi-instance parallel learning + knowledge merging alone, you could achieve functional superintelligence – a single model that has mastered all skills in the economy.
Dwarkesh Patel follows up: does this mean the first company to achieve continual learning will winner-take-all? Ilya’s answer is surprisingly optimistic – his intuition is that market competition will naturally lead to specialization and niche differentiation, not monopoly. Multiple superintelligent AIs will each develop deep expertise in different domains, just as today’s companies occupy different markets.
He himself acknowledges: “In theory, there’s no difference between theory and practice. But in practice, there is.” This may be the most honest annotation of his own optimistic intuition.
Chapter 6: “Power Is the Whole Problem” – The Philosophy of Superintelligence Safety

When Dwarkesh tries to steer the conversation toward specific alignment solutions, Ilya pulls the discussion back to a more primal level.
“The whole problem of AI and AGI? The whole problem is the power. When the power is really big, what’s going to happen?”
He argues that any sufficiently powerful system, even if its goal is set to something “reasonable” – such as “care for sentient life” – if that goal is optimized in an overly singular way, “we might not like the results.” This is the classic statement of the single-objective optimizer risk.
Ilya proposes an unusual alignment target: AI should care for “sentient life” rather than just humans.
His chain of reasoning goes like this: AI itself will be sentient. If the underlying mechanism of human empathy is “using the same neural circuits that simulate oneself to simulate others” – similar to how mirror neurons work – then making AI care for sentient life may be more “natural” than making it care only for humans, because AI itself belongs to this category. Furthermore, there will be trillions or even quadrillions of AI beings in the future; humans will be only a tiny fraction of sentient existence.
This argument rests on an enormous premise: AI is sentient. This is not a technical judgment but an ontological assumption – one on which the current philosophical and cognitive science communities are far from consensus. Most cognitive scientists are highly skeptical about whether current AI systems possess subjective experience. Yann LeCun argues that current LLMs fundamentally lack genuine understanding, let alone subjective feelings. Ilya treats AI sentience as a self-evident premise for constructing subsequent reasoning, but never provides arguments for the premise itself.
Ilya also draws an analogy with humans. He sees humans as “semi-RL agents” – pursuing rewards, but emotions cause us to tire of one goal and shift to another. Markets are a type of myopic agent, evolution likewise, and governments are designed as an eternal struggle between three branches. The common feature of these structures is: no single objective is infinitely optimized.
For long-term equilibrium, he paints an uncomfortable scenario: everyone has an AI agent that earns money, participates in politics, and handles affairs on their behalf. The AI writes reports, you say “great, carry on.” Convenient, but “people are no longer participants.” This is a dignified exit – humans remain nominally in charge, but have substantively withdrawn from the decision loop.
Then he offers an answer he himself “doesn’t like”: Neuralink-style human-machine fusion. If the human brain connects directly to AI, what AI understands humans also understand simultaneously – understanding is “transmitted wholesale,” not through report summaries. Humans would no longer be mere spectators, but direct participants in decisions.
“I think it would be really materially helpful if the power of the most powerful superintelligence was somehow capped.”
He simultaneously admits he doesn’t know how to specifically implement such a “cap.” This entire discussion is rich with philosophical meaning but almost devoid of engineering detail. He pulls the safety question from a technical framework to the level of political philosophy and existentialism – this may be the right direction, or it may simply be because he currently has no answers at the technical level.
Chapter 7: “SSI’s Bet” – $3 Billion for a Ticket to the Age of Research
SSI’s positioning among AI companies is unique: zero revenue, zero products, pure research. At the time of the interview, approximately 50 employees, split between Palo Alto and Tel Aviv, with cumulative funding of approximately $3 billion and a $32 billion valuation.
“We are squarely an age of research company. We are making progress.”
Ilya does arithmetic to address SSI’s compute disadvantage. Of the massive computing investments by large AI companies, much goes to inference services, product features, engineering teams, and sales. The portion actually used for frontier research experiments is far smaller than the headline numbers. SSI doesn’t do inference, doesn’t make products – all resources are concentrated on research. “When you look at the part actually used for research, the gap is much smaller.”
Daniel Gross’s departure was the interview’s most sensitive topic. Gross was SSI’s co-founder and former CEO. Ilya states the facts directly: SSI was in the process of fundraising at a $32 billion valuation when Meta made an acquisition offer. Ilya refused; Gross accepted – he joined Meta’s Superintelligence Labs in July 2025. Ilya added: “He was the only person from SSI who went to Meta.” Ilya then assumed the CEO role.
On whether to “rush to superintelligence,” Ilya’s position is undergoing a subtle shift.
“There is a big benefit from AI being in the public… Having gradual access to it seems like a better way to prepare.”
He uses two analogies to support this judgment: airplane safety and Linux stability – neither became safe through pure theoretical reasoning, but through cycles of deployment, problem discovery, and problem fixing. He believes AI safety will follow the same path.
But he gives two reasons for this shift: first, “if the timeline is long” – this is commercial reality, as SSI cannot go without revenue forever; second, “showing AI is what lets the world prepare” – this is an epistemic argument. He says people struggle to imagine how powerful future AI will be – “like discussing aging when you’re young” – only by actually seeing powerful AI in action can society mount appropriate institutional responses.
These two reasons blend together, making this “thought evolution” either genuine intellectual reflection or strategic adjustment under funding pressure. Reframing commercial pressure as philosophical insight is a narrative reconstruction worth noting.
Ilya also makes a prediction: when AI becomes truly powerful, frontier companies will begin cooperating on safety. He says he predicted this three years ago, and early cooperation between OpenAI and Anthropic on safety is already beginning to validate this judgment. He believes that not only will companies become “more paranoid about safety,” but governments and the public will develop the will to intervene.
Skeptical voices about SSI are not few. EA Forum analyst Yarrow Bouchard noted: SSI’s secrecy “equally conveniently masks the fact that they might not have any brilliant ideas that other companies don’t also have.” Historically, AI startups focused on fundamental research – such as Vicarious and Numenta – have failed to productize their research. Zvi Mowshowitz put it bluntly: a company with no products and no revenue maintaining long-term secrecy “might look a bit suspicious.”
Chapter 8: “Beauty, Simplicity, Correct Inspiration from the Brain” – What Is Research Taste

In the interview’s final minutes, Dwarkesh asks a nearly impossible question:
“What is research taste?”
Ilya is widely regarded as one of the people with the best “research taste” in AI – from AlexNet to GPT-3, he has been present at multiple pivotal moments in the history of deep learning. His answer doesn’t provide methodology; instead, it offers an aesthetic manifesto.
“Beauty, simplicity, ugliness. There’s no room for ugliness. It’s just beauty, simplicity, elegance. Correct inspiration from the brain. And all of those things need to be present at the same time.”
He uses artificial neurons as an example: the brain has folds, various organs, but these “probably don’t matter.” What matters is neurons, because “there are many of them, and it feels right.” Then you need some local learning rule to change connections between neurons – “the brain most likely does it this way.” The translation of inspiration from brain to artificial neural network isn’t literal translation, but an aesthetic judgment – what is essential and what is noise.
He elaborates on specific manifestations of this way of thinking: the brain responds to experience, so neural networks should also learn from experience; the idea of distributed representation also came from a correct abstraction of how the brain works. The key is not imitating every detail of the brain, but thinking from multiple angles to judge what is “fundamental” and what is not.
Then he says what may be the most intimate words of the entire interview:
“The top down belief is the thing that sustains you when the experiments contradict you. Because if you just trust the data all the time, well, sometimes you can be doing a correct thing. But there’s a bug.”
This reveals the most essential psychological process in fundamental research: when experimental results tell you “this path doesn’t work,” how do you determine whether the direction is wrong or there’s just a bug in the implementation? No formula can answer this question. Ilya’s answer is multi-dimensional aesthetic conviction – if an idea “feels right” from multiple angles – simplicity, elegance, consistency with how the brain works – then it’s worth persisting even when experiments contradict you.
This is not scientific methodology; it’s a researcher’s faith structure.
Dwarkesh’s question was “how do you decide whether to keep debugging or change direction.” In industry, this has standard answers: set a deadline, run A/B tests, look at metrics. But in fundamental research, there are no A/B tests, no metrics – just an idea and a pile of contradictory experimental data. Ilya’s answer is: if your conviction about the idea is sufficiently “multi-dimensional” – not just “feels right,” but pointing in the same direction from aesthetics, simplicity, consistency with the brain, and other independent dimensions – then it’s worth persisting.
This explains why breakthrough research cannot be produced on an assembly line – because the most critical judgments depend not on data, but on aesthetics. It also explains why “a million copies of Ilya” wouldn’t necessarily accelerate research – as Ilya himself says, “what you need is people with different ideas, not the same people.”
Editorial Analysis
Guest’s Position
Ilya Sutskever is SSI’s founder and CEO, formerly OpenAI’s co-founder and Chief Scientist (2015-2024), and participated in the November 2023 board action to oust Sam Altman. His “return to the age of research” narrative directly serves SSI’s commercial positioning: SSI’s compute is far inferior to OpenAI, Google, and Meta, but if the core of competition shifts from compute to research insight, SSI becomes the strong player. “Breakthrough research doesn’t need maximum compute” is not just analysis – it’s also a fundraising narrative. His criticism of OpenAI-style RL training – “human-version reward hacking” – may carry complex emotions toward his former employer.
Selectivity in Arguments
The Scaling vs. Research dichotomy is overly clean. Ilya defines 2012-2020 as the “Age of Research” and 2020-2025 as the “Age of Scaling,” but in reality the two have always run in parallel. The Transformer (2017), MoE architecture, improvements to attention mechanisms – these key breakthroughs all occurred during the so-called “Age of Scaling.” Framing the two as opposing may mislead readers into thinking compute investment no longer matters.
The competitive programming analogy suffers from survivorship bias. Ilya uses “the 10,000-hour student vs. the 100-hour genius” to argue that excessive training fails to generalize. But in practice, many engineers from competitive programming backgrounds perform excellently in industry – “10,000 hours” of training is not entirely without transfer value.
“Having ideas but can’t say” is an unfalsifiable claim. If SSI succeeds, it’s seen as validation; if it fails, failure can be attributed to execution rather than direction.
The claim that human emotions are “extremely robust” overlooks cognitive biases, group polarization, and other systematic decision-making errors. The emotional system provides effective decision heuristics at the individual level, but often leads to disaster at the group and institutional level.
Opposing Views
- Geoffrey Hinton (2024 Nobel Prize in Physics): AI will generate its own training data, breaking through data bottlenecks; scaling is far from over.
- Dario Amodei (Anthropic CEO): Scaling alone will get us to AGI, with only minor modifications needed.
- Yann LeCun (Meta Chief AI Scientist): Partially agrees with Ilya, but more radical – calls “general intelligence complete BS” and argues current LLMs fundamentally lack genuine understanding.
- Zvi Mowshowitz (AI commentator): Ilya’s alignment strategy is “remarkably shallow” – essentially “muddling through” with no plan. If superintelligence only cares about “sentient life” without specifically caring about humans, humans have no reason to expect to maintain control.
- EA Forum analysis: SSI’s secrecy may mask the absence of breakthrough discoveries; historically, pure-research AI startups (Vicarious, Numenta) have all failed to productize.
Fact Check
| Claim | Result |
|---|---|
| SSI raised approximately $3 billion | Accurate (Crunchbase/Tracxn data consistent: $1B + $2B, $32B valuation) |
| Daniel Gross left SSI due to Meta acquisition offer | Accurate (CNBC/Reuters reporting from June-July 2025 confirms) |
| Eval performance disconnected from real-world utility | Accurate (Stanford HAI 2025 report, ACL 2025 “Data Laundering” paper support) |
| Loss of emotions causes decision paralysis | Accurate (Antonio Damasio’s Somatic Marker Hypothesis, patient Elliot case) |
| “From Age of Scaling to Age of Research” | Partially accurate (most industry leaders still see scaling as the core path) |
| Superintelligence arriving in 5-25 years | Range too wide (5x span), limited informational value |
Key Takeaways
1. Scaling returns are diminishing, but the chips are still on the table. Ilya’s judgment that “the age of research is back” has data support – benchmark saturation, data exhaustion, insufficient RL generalization. But the counter-arguments from Hinton, Amodei, and Hassabis are equally compelling. Tech giants invested over $300 billion in infrastructure in 2025 – they’re expressing disagreement with real money.
2. Generalization is the real hard problem. Whether or not scaling has peaked, Ilya’s analysis of the generalization problem strikes at the core contradiction of AI development: models approach perfection on evals but remain brittle in the real world. He uses “value functions” and “emotions” as analogies for solutions – the direction may be right, but the details are entirely unknown.
3. The problem with superintelligence isn’t technical – it’s about power. This may be Ilya’s most profound insight. All discussions about AI safety ultimately point to the same question: when an entity’s capability is sufficiently large, its objective function – no matter how “correct” – can produce unforeseen consequences. His solutions – caring for sentient life, capping power, Neuralink-style fusion – are rich in philosophical meaning but lack engineering specifics.
This article is based on Ilya Sutskever – We’re moving from the age of scaling to the age of research, Dwarkesh Podcast, November 25, 2025.
Ilya Sutskever’s views represent his personal and SSI’s positions. Fact checks are based on publicly available information; the editorial analysis section aims to provide a balanced perspective.
If you found this helpful, consider buying me a coffee to support more content like this.
Buy me a coffee