别再 Prompt 了,开始工程化:Drew Knox 的 Context as Code 方法论
别再 Prompt 了,开始工程化:Drew Knox 的 Context as Code 方法论
演讲者: Drew Knox — Tessl 产品设计负责人(前 Grammarly 语言模型研究科学家) 来源: AI Native Dev | 时长: 29:36 完整转录:带章节的全文转录
导读
Drew Knox 目前是 Tessl(一家 context engineering 工具公司)的产品设计负责人。在此之前,他在 Grammarly 领导语言模型研究团队,后来又在 AI-first 社交网络 Cantina 做研究科学家。这个背景让他同时具备 ML 研究视角和产品落地经验——当然,也让他有足够的动机为 Tessl 的产品方向做布道。
这场近 30 分钟的演讲提出了一个完整的类比框架:如果 Context 是你的新代码,那么软件工程生命周期(SDLC)的每个环节——静态分析、单元测试、集成测试、可观测性、CI/CD、包管理——都应该有 Context 版本。 Knox 逐一拆解了这六个类比,给出了具体的操作建议,并在 Q&A 环节回应了关于模型进步是否会让这一切变得多余的尖锐问题。
本文的编者分析部分会审视 Knox 作为 Tessl 产品负责人的利益相关性,以及 SDLC 类比框架的局限。
目录
- “Context 是新的代码” — 从 IC 到 Tech Lead
- 三大挑战:非确定性、评分困难、同步问题
- 静态分析:让 Context 通过"编译"
- Evals:你的 Context 真的有用吗?
- Repo Evals:全环境压力测试
- 可观测性:Agent 日志是金矿
- 包管理器:Context 的 npm
- Q&A 精华:三个值得深思的问题
- 编者分析
- 核心建议
“Context 是新的代码” — 从 IC 到 Tech Lead
Knox 的开场颇有挑衅性:
“We have effectively had general purpose agentic development machines for 50 years. We just called them software engineers.”
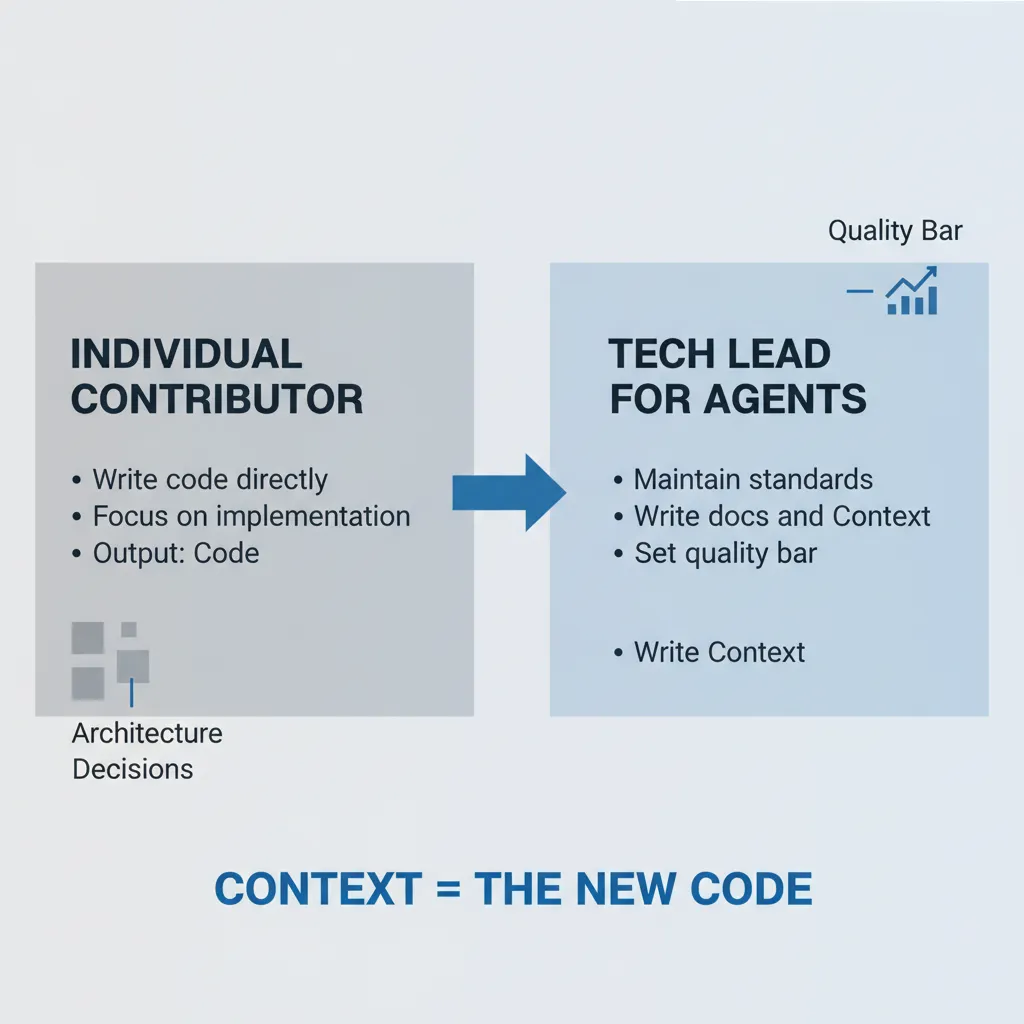
他的核心论点是一个角色转变的叙事。过去,开发者是 IC(Individual Contributor),价值体现在写出好代码。现在,随着 Agent 能力的提升,开发者正在变成 Tech Lead——工作不再是亲手写代码,而是确保好代码能被写出来。
这意味着什么?Knox 列举了 Tech Lead 的核心职责:维护标准、做架构决策、写文档、为团队提供上下文、设定质量门槛。这些事情,现在要对 Agent 做一遍。
“Context is in some sense our new code.”
如果接受这个类比,自然的追问是:代码有编译器、有测试框架、有 CI/CD、有包管理——Context 的基础设施在哪? 这正是 Knox 接下来 20 分钟要回答的问题。
三大挑战:非确定性、评分困难、同步问题
在展开 SDLC 类比之前,Knox 先承认了三个让 Context Engineering 不同于传统软件工程的结构性挑战。
第一,非确定性。 LLM 不像编译器——同样的输入不保证同样的输出。你不能跑一次 Agent,成功了就说"我的 Context 是好的"。这要求所有验证都必须是统计性的,需要多次运行取平均值。
第二,没有唯一正确答案。 如果你写了一份代码风格指南,Agent 的产出可能在语法上正确但风格完全不对。你无法用 assert output == expected 来判定。Knox 认为这让传统 unit test 变得不够用,需要更灵活的评估方式。
第三,同步问题。 Context 描述的是其他事物(API、库、内部流程),而这些事物会变化。你改了一个 API,对应的 Context 文件需要同步更新——否则 Agent 会按过时的文档行事。这是代码没有的新型"技术债"。
Knox 承认这三个挑战让类比不完美,但他的立场是:有不完美的工程框架,远好过没有框架。
静态分析:让 Context 通过"编译"
Knox 的第一个类比是静态分析——在不运行 Agent 的情况下,检查 Context 是否符合基本规范。
他举了一个真实案例:某 Tessl 客户在 skill 文件中不小心加了一个 @ 符号,触发了 import 机制,导致一系列 context 文件加载失败——而他们完全没意识到。Knox 的评价是:“你会惊讶有多少人的 context 根本没有被加载,而他们毫不知情。”
具体做法分两层:
- 格式验证——检查 skill 文件是否"编译通过"。Skills 标准有参考 CLI 实现可以做这个检查。Knox 认为这应该放进 CI/CD,每次 skill 文件变更自动触发。
- Best Practices 检查——把 Anthropic 的 best practices 文档作为 prompt,用 LLM-as-judge 评估 context 的质量:是否足够具体?是否有明确的触发条件?是否有实际案例?
Knox 把这一层称为 “table stakes”(底线要求)。成本低、速度快、可以放进 CI/CD 自动运行。附加好处是:静态分析的输出可以直接喂给 Agent 让它自动修复——形成一个快速迭代循环。
Evals:你的 Context 真的有用吗?
这是 Knox 花时间最多的部分,也是他认为最关键的环节。核心问题是:你的 Context 到底有没有帮到 Agent?
方法论上,Knox 推荐的流程是:
- 定义任务场景——写一些现实的开发任务,这些任务需要用到你的 Context(比如"用我们的内部 logging 库记录一条错误日志")。
- 定义评分 rubric——不是 unit test,而是一份描述"好的解决方案长什么样"的评分标准。比如:“应该使用
logger.error()而不是print()"、“应该在初始化之前调用configure()"。 - 有/无 Context 对比——分别在有和没有 Context 的情况下运行 Agent,比较得分。
Knox 解释了为什么不用 unit test 而用 rubric:
“Agents do unspeakable things to get unit tests to pass.”
Agent 会 hack 测试——为了通过断言而走捷径,比如硬编码预期输出或跳过实际逻辑。Rubric 更灵活,可以评估"是否写了地道的代码”、“是否使用了指定的库"这类无法用断言捕获的质量维度。
在 Q&A 环节,有人问非二元评分是否有效。Knox 的回答很直接:Agent 基本只得 0 分或满分,二元评分足够。 Tessl 提供了更细粒度的打分选项,“but if you look, agents pretty much always score zero or max score.”
Knox 还分享了两个实用发现:
- 每段 Context 大约需要 5 个 eval 场景就能获得可靠的衡量基准。前期投入大,但之后可以反复使用。
- 随着模型升级,定期重跑 evals 可以帮你删除不再需要的 Context。 他举例:Python 风格指南在半年前很重要,但 Claude Opus 4.6 已经能写出很好的 Python,不再需要额外指导。反过来,某个版本的 Gemini 出现了回归——“觉得自己不需要读 context”——evals 帮他们及时发现了这个问题。

Repo Evals:全环境压力测试
单段 Context 的 eval 只能告诉你"这段内容本身是否有效”。Knox 认为还需要更高一层的测试:在完整的代码环境中、加载所有 Context 的情况下,Agent 还能正常工作吗?
他提到了一个概念叫 “dumb zone”(引自当天另一场演讲)——当 context window 被工具、文档、各种 context 文件塞满时,Agent 的表现会持续恶化。太多 context 反而比太少更糟。
具体做法是:
- 为你的 repo 设计 5 个典型开发任务作为基准。
- 用评分 rubric 打分,定期运行。
- 一个巧妙的做法是扫描历史 commit,把真实的代码变更转化为 eval 任务。定期从最近一个月的 commit 中随机抽 5 个刷新 eval 套件,避免测试集过时(Knox 类比为 ML 中的 input drift)。
这一层测试的目的不是验证单段 context 的质量,而是监控整体系统的健康度:context 是否过多?工具是否过载?技术债是否已经积累到 Agent 无法理解的地步?
可观测性:Agent 日志是金矿
Knox 认为大多数团队坐在一座金矿上而不自知:所有 Agent 的 chat logs 都以文件形式存在可访问的位置。
他的建议非常具体:
- 让团队成员运行一个简单的脚本,聚合各自机器上的 Agent 日志。
- 搜索特定模式来发现 context 缺失或错误:Agent 道歉的次数(搜索 “sorry”、“you’re absolutely right”)、工具调用频率、特定库的使用模式。
“I guarantee you’ve got like three or four months of cursor logs sitting on all your devs machines that you could mine for.”
Knox 还给出了另一个可操作的建议:在 CI/CD 中设置 context 自动更新。 每当有 PR 提交时,让一个 Agent 扫描变更内容,检查是否有需要同步更新的 markdown 文件。他说这比想象中有效:“因为 PR 通常很聚焦,Agent 很擅长找到需要更新的地方。”
在这个环节,Knox 发出了最强的一句警告:
“As your context gets out of date, it just destroys agent performance. So if you’re going to write context, you have to have a solution for keeping it up to date.”
他的态度很明确:不要指望手动更新,因为你不会做。自动化是唯一可行的方案。

包管理器:Context 的 npm
Knox 最后讨论了 context 的复用问题。如果你写了一份 React best practices 或 code review 指南,你希望它可以在多个项目间共享,就像 npm 包一样。
当前生态中,skills.sh 是最流行的 context 包管理器(Knox 承认这一点时显得有些不情愿),Tessl 也有自己的 Context Registry。
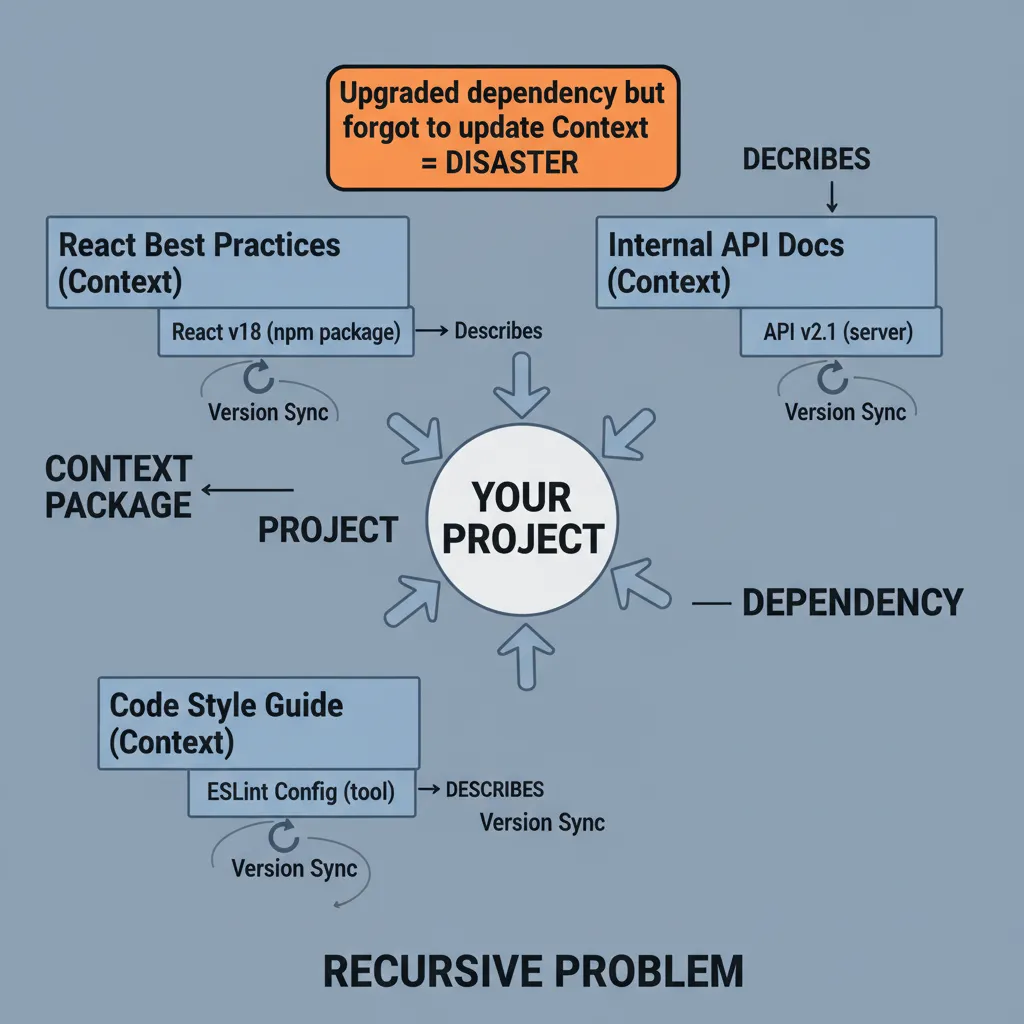
Knox 指出了一个 context 包管理独有的递归问题:你安装的 context 经常是在描述其他包管理器中的包。 比如你装了一个"PyPI 某库的使用文档”,这份 context 描述的是特定版本的库。如果你升级了库但没更新 context,Agent 就会按旧版本的 API 来写代码。
这是传统包管理不存在的问题:npm 包之间的依赖是代码级的,版本锁定是自动的。但 context 对外部依赖的"引用"是语义级的——目前没有自动的版本锁定机制。
Knox 坦言整个包管理生态还处于极早期(“最近两三周才爆发”),但他认为开发者需要开始考虑这个问题。
Q&A 精华:三个值得深思的问题
演讲的最后七分钟是 Q&A,其中有三个问题触及了 Context Engineering 的深层问题。
问题一:模型进步会让这些脚手架消失吗?
Knox 的回答分了两层。会减少的:通用知识型 context(如 Python 风格指南)随着模型能力提升会变得不必要。不会消失的:自定义内部逻辑(你的 logging 方案、你的内部 API)永远不在模型的训练数据里,必须显式告知。
他预测未来方向是 progressive disclosure:不再把所有 context 塞进 context window,而是做路标式的指引,Agent 觉得需要时自己去查。大量 context 会从"写入时"移到"审查时"——不教 Agent 怎么做,而是在它做完后检查是否符合标准。
问题二:评分必须是二元的吗?
Knox 确认了:实际上是的。 Agent 要么完全搞砸(0 分),要么做得很好(满分),中间地带很少。这是一个有点反直觉的发现——你可能以为 Agent 会"部分正确",但实际上它更像一个全有或全无的系统。
问题三:非技术人员什么时候可以不需要理解 Agent?
Knox 引用了他妻子(Meta Staff Engineer)的话:
“If you cloned me, I would still code review my code.”
他的答案是:永远需要技术管家。 但角色会变化——从现在的"1 Tech Lead 管 5-10 工程师"反转为"1 技术管家 + 5-10 产品/设计探索者"。技术管家的工作是总体系统设计、持续审查 Agent 代码、识别共性失败点并抽象为可复用组件。时间线?Knox 说"可能单位数年",对 AI-native greenfield 项目可能在一年内。
编者分析
演讲者立场
Knox 是 Tessl 产品设计负责人,Tessl 是一家 context engineering 工具公司。将 context engineering 包装为一套完整的、可类比 SDLC 的方法论,直接利好 Tessl 的产品叙事。Knox 在演讲中多次使用"你可以自己做这些,但 Tessl 做得更好"的话术(“There’s other tools that do a lot of this. Not as well as Tessl though obviously”),这种自我意识的幽默降低了推销感,但利益相关性是真实存在的。
论证中的选择性
Knox 的 SDLC 类比框架是这场演讲最大的贡献,也是最大的风险。框架的优点在于降低了 context engineering 的认知门槛——如果你理解静态分析,你就能理解 context 验证。但类比也在暗示一种不存在的确定性。
几个缺失:
- 没有 ROI 数据。 “每段 context 写 5 个 eval"听起来合理,但对一个 50 人的工程团队来说,投入产出比是多少?Knox 没有提供任何数据。
- 二元评分的结论可能有采样偏差。 Tessl 的客户群倾向于使用结构化 context 做定义良好的开发任务——在这种场景下,Agent 确实更可能表现为全有或全无。但对于更模糊的创意型任务(如 UI 设计、文案撰写),评分分布可能完全不同。
- “dumb zone"问题被提到但没有解决。 Knox 说 context 过多会导致 Agent 进入"dumb zone”,但没有给出如何判断和应对的方法——除了"跑 repo evals 看看”。
- 隐私问题轻描淡写。 聚合团队成员的 Agent 日志涉及代码和对话隐私,Knox 只说了"opt-in, of course"就带过了。
反面观点
有一个更根本的问题 Knox 没有正面回答:Context Engineering 是否是过渡期产物? 他自己在 Q&A 中承认,Python 风格指南已经不再需要,未来需要 context 的场景会越来越少。如果这个趋势持续下去,那现在投入大量资源建设 context 基础设施,可能在两年后大部分变得多余。
另一个隐含的张力是:将非确定性系统强行套入确定性工程框架,可能误导开发者对可靠性的预期。 静态分析能保证代码编译通过,但"context 静态验证"只能保证格式正确——它无法保证 Agent 会按你期望的方式使用这段 context。这个差距比 Knox 暗示的要大。
值得借鉴的部分
批评归批评,Knox 的框架仍然有实用价值。几个立即可用的建议——在 CI/CD 中加入 context 格式验证、搜索 Agent 日志中的道歉词、PR 时自动检查 context 是否需要更新——这些成本低、收益明确,不需要购买 Tessl 就能做。把 context engineering 从"玄学调 prompt"拉回到可衡量、可测试、可自动化的工程实践方向,这个大方向是对的。
核心建议
- 从静态验证开始——把 skill/context 文件的格式检查放进 CI/CD。成本最低,收益最快。Knox 说"你会惊讶有多少人的 context 根本没加载"。
- 写 eval 而不是 unit test——为每段关键 context 设计 5 个任务场景和评分 rubric,跑有/无 context 对比。Agent 会 hack unit test,但 rubric 更难作弊。
- 挖掘 Agent 日志——搜索 “sorry”、“you’re absolutely right” 来发现 context 缺失。你的团队可能有 3-4 个月的 Cursor 日志从未被分析过。
- 自动化 context 更新——在 CI/CD 中加入"PR 变更 → 检查相关 context 是否需要更新"的流程。Context 过时比缺失更危险。
- 定期清理——随模型升级重跑 evals。能删就删。每一段不必要的 context 都是浪费的 token 和潜在的干扰。
整理自 Stop Prompting, Start Engineering,2026-02-27
如果这篇文章对你有帮助,欢迎请我喝杯咖啡,支持我继续创作更多内容。
Buy me a coffee