文件系统即数据库:我如何为 AI Agent 构建个人操作系统

每次 AI 对话都以同样的方式开始。你解释自己是谁,你在做什么,你粘贴进写作风格指南,你重新描述自己的目标。你给出昨天、前天、大前天已经给过的相同上下文。然后 40 分钟后,模型忘记了你的声音,开始写得像新闻稿一样。
我受够了。所以我构建了一个系统来解决这个问题。
我称之为 Personal Brain OS。这是一个基于文件的个人操作系统,存放在一个 Git 仓库里。克隆它,在 Cursor 或 Claude Code 中打开,AI 助手就拥有了一切:我的声音、我的品牌、我的目标、我的人脉、我的内容生产线、我的研究、我的失败记录。没有数据库,没有 API 密钥,没有构建步骤。只有 80 多个 Markdown、YAML 和 JSONL 文件,人类和语言模型都能原生读取。
我将分享完整的架构、设计决策和踩过的坑,这样你就能构建自己的版本。不是我的复制品,而是你自己的。具体的模块、文件 schema、skill 定义在你的工作中会有所不同。但模式是可迁移的。为 AI Agent 结构化信息的原则是通用的。拿走适合你的,忽略不适合的,然后构建出一个让你的 AI 真正有用而非泛泛而谈的系统。
以下是我如何构建它、为什么架构决策很重要,以及我从中艰难学到了什么。
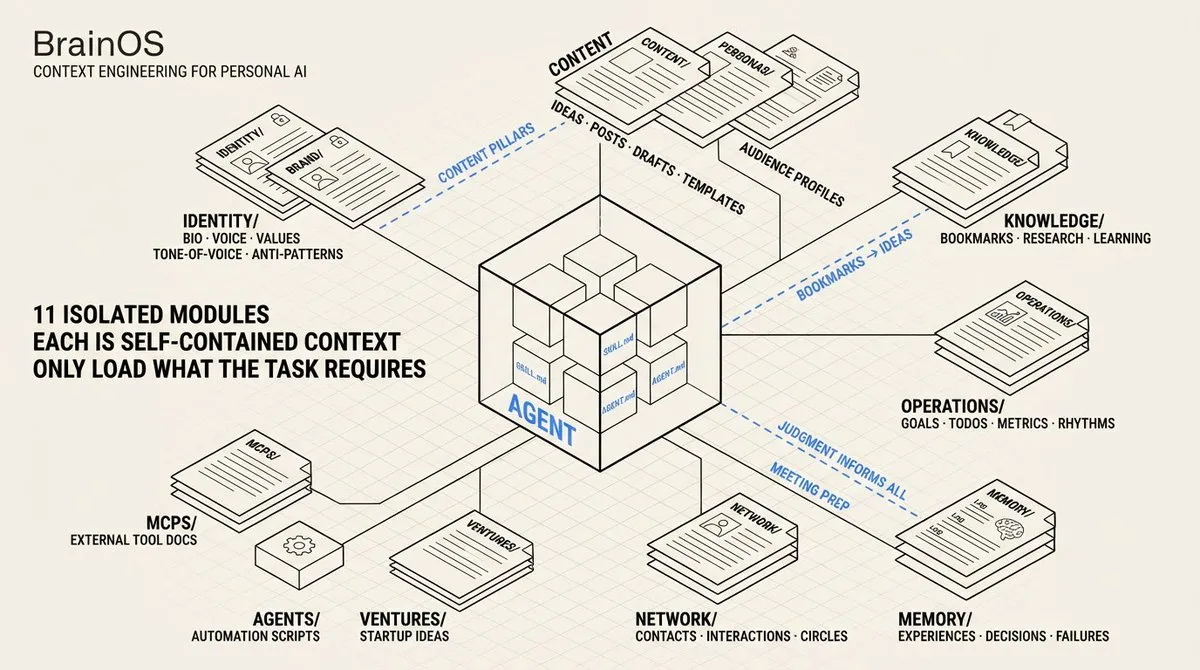
1) 核心问题:上下文,而非 Prompt
大多数人认为 AI 助手的瓶颈在于提示词。写一个更好的 prompt,就能得到更好的回答。这在单次交互和生产级 agent prompt 中确实如此。但当你希望 AI 在数周数月中跨越数十个任务以你的身份运作时,这套逻辑就崩塌了。
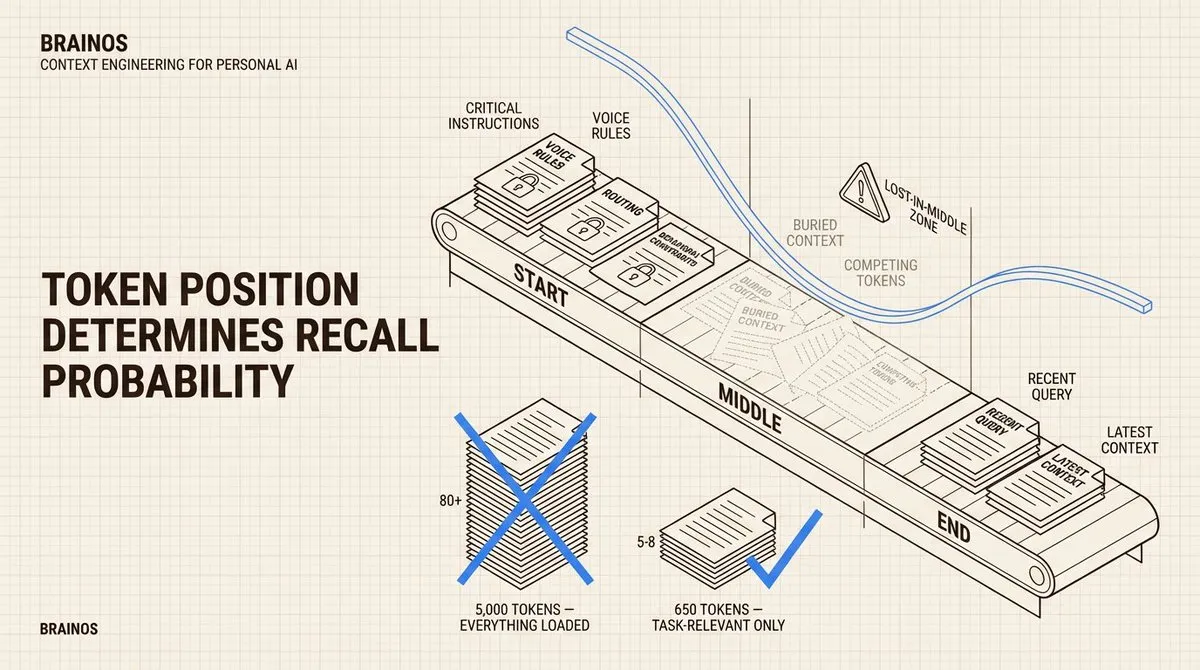
注意力预算: 语言模型的上下文窗口是有限的,而且并非所有部分的效果相同。这意味着把你知道的一切都塞进 system prompt 不仅是浪费,而且会主动降低性能。你添加的每个 token 都在争夺模型的注意力。
我们的大脑也类似。当有人在会议前花 15 分钟向你做简报时,你记住的是他们说的第一件事和最后一件事,中间的都模糊了。语言模型有同样的 U 型注意力曲线,只是它们的曲线可以被数学测量。Token 位置影响召回概率。更新的模型在这方面有所改进,但你仍然在分散模型对最重要事项的关注。了解这一点会改变你为 AI 系统设计信息架构的方式。
我没有写一个巨大的 system prompt,而是将 Personal OS 拆分成 11 个隔离的模块。当我要求 AI 写博客时,它加载我的声音指南和品牌文件。当我要求它准备会议时,它加载我的联系人数据库和互动历史。模型在内容任务中永远看不到人脉数据,在会议准备任务中永远看不到内容模板。
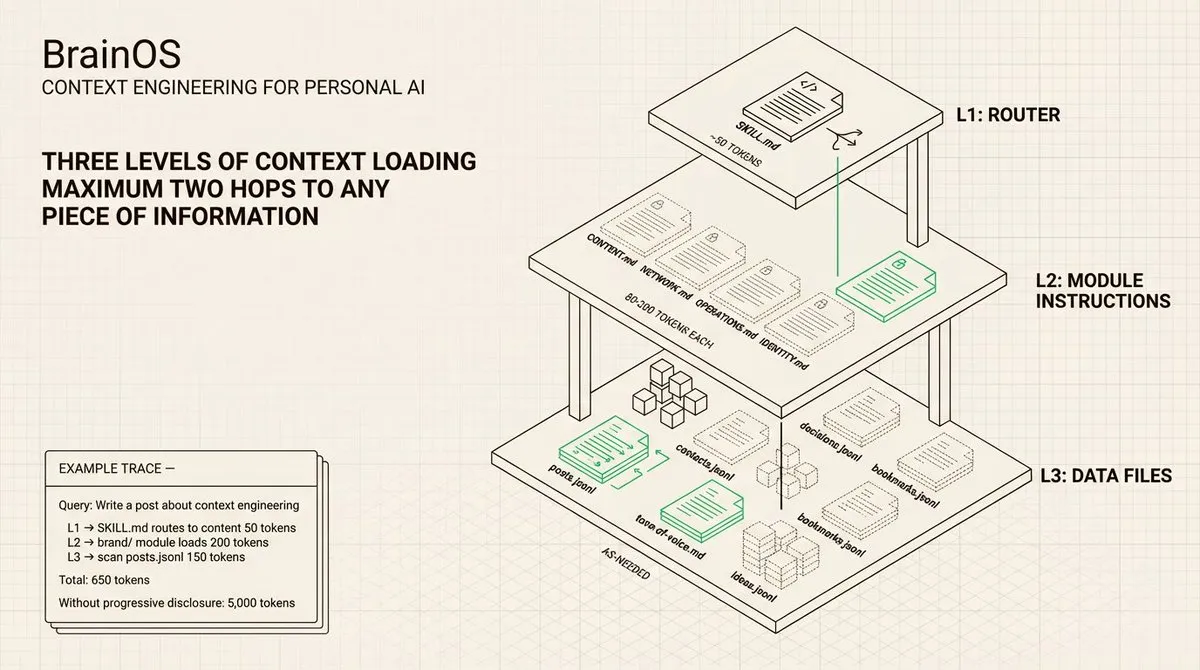
渐进式加载(Progressive Disclosure): 这是使整个系统运作的架构模式。系统不会一次性加载所有 80 多个文件,而是使用三个层级。第一层是一个轻量级的路由文件,始终加载,告诉 AI 哪个模块相关。第二层是模块特定的指令,仅在需要该模块时加载。第三层是实际数据 – JSONL 日志、YAML 配置、研究文档 – 仅在任务需要时加载。
这反映了专家的工作方式。三个层级创建了一个漏斗:广泛路由,然后是模块上下文,最后是具体数据。在每一步中,模型都精确地获得它需要的内容,不多不少。
我的路由文件是 SKILL.md,告诉 agent「这是内容任务,加载品牌模块」或「这是人脉任务,加载联系人」。模块指令文件(CONTENT.md、OPERATIONS.md、NETWORK.md)每个 40-100 行,包含文件清单、工作流序列和一个带有该领域行为规则的 <instructions> 块。数据文件最后加载,仅在需要时。AI 逐行从 JSONL 读取联系人,而不是解析整个文件。三个层级,任何信息最多两跳即可到达。
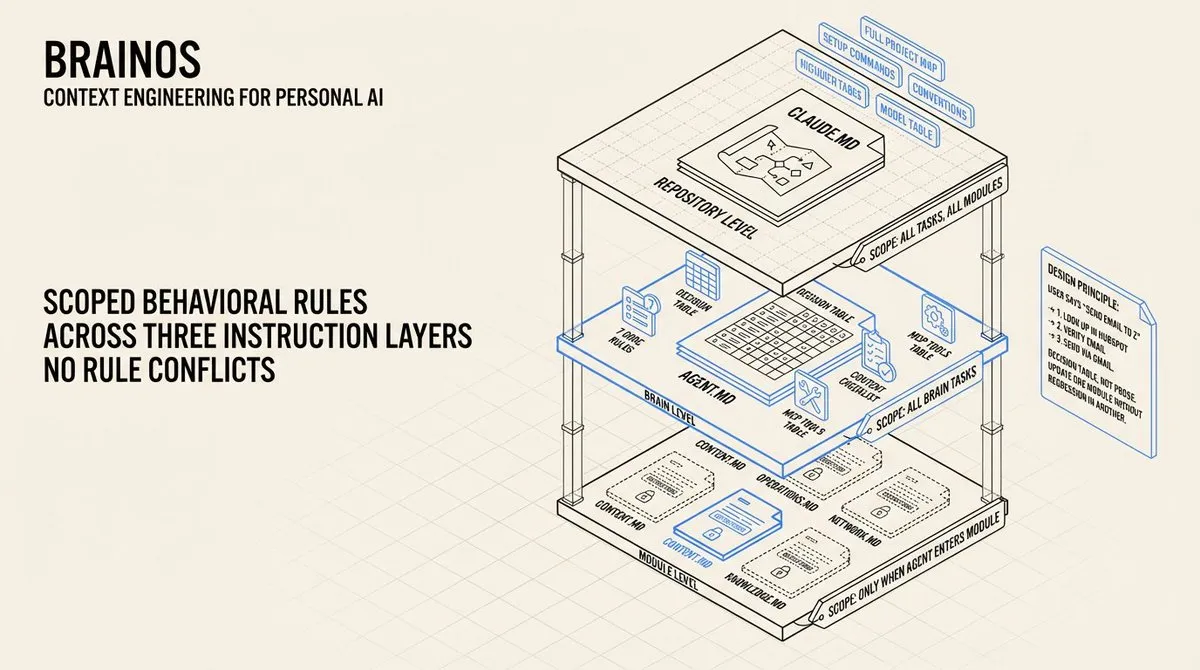
Agent 指令层级: 我构建了三层指令来限定 AI 在不同层级的行为方式。在仓库层级,CLAUDE.md 是入职文档 – 每个 AI 工具首先读取它,获取项目的完整地图。在大脑层级,AGENT.md 包含七条核心规则和一个决策表,将常见请求映射到精确的操作序列。在模块层级,每个目录都有自己的指令文件,带有领域特定的行为约束。
这解决了困扰大型 AI 项目的「指令冲突」问题。当所有内容都放在一个 system prompt 中时,规则会互相矛盾。内容创作指令可能与人脉管理指令冲突。通过将规则限定在各自的领域,你消除了冲突,给 agent 清晰、不重叠的指导。层级结构还意味着你可以更新一个模块的规则,而不会影响另一个模块的行为。
我的 AGENT.md 是一个决策表。AI 读到「用户说’给 Z 发邮件’」,立即看到:
- 第一步,在 HubSpot 查找联系人。
- 第二步,验证邮箱地址。
- 第三步,通过 Gmail 发送。
模块级文件如 OPERATIONS.md 定义了优先级(P0:今天做,P1:本周,P2:本月,P3:待办),这样 agent 就能一致地分类任务。agent 遵循与我相同的优先级系统,因为这个系统是被编码的,而非隐含的。
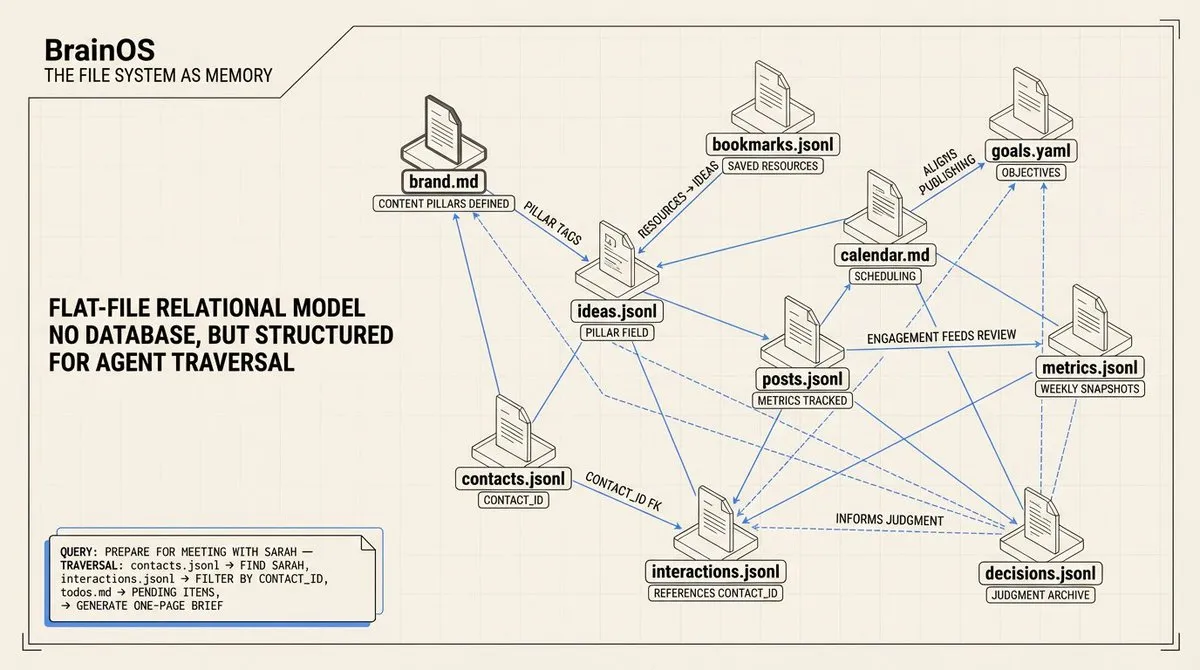
2) 文件系统即记忆
我做出的最反直觉的决定之一:不用数据库。不用向量存储。除了 Cursor 或 Claude Code 自带的功能外,不用任何检索系统。只是磁盘上的文件,用 Git 做版本控制。
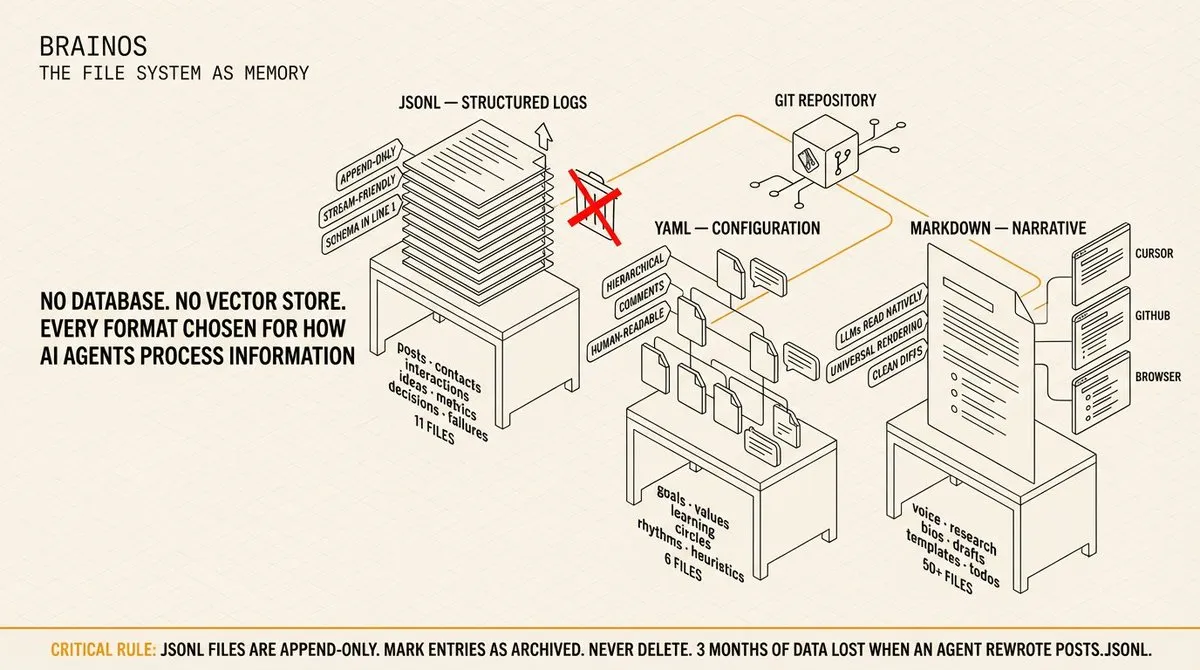
格式-功能映射: 系统中每种文件格式都是基于 AI Agent 处理信息的方式精心选择的。JSONL 用于日志,因为它天生是 append-only 的,对流处理友好(agent 逐行读取,无需解析整个文件),每一行都是独立的有效 JSON。YAML 用于配置,因为它能干净地处理层级数据,支持注释,人机可读,没有 JSON 括号的噪音。Markdown 用于叙述,因为 LLM 原生读取,到处可渲染,在 Git 中产生干净的 diff。
JSONL 的 append-only 特性防止了 agent 意外覆盖历史数据的一类 bug。我见过 JSON 文件出这种事 – agent 重写整个文件,丢失三个月的联系人历史。使用 JSONL,agent 只能添加行。删除通过标记条目为 "status": "archived" 来实现,这保留了完整的历史记录用于模式分析。YAML 的注释支持意味着我可以在目标文件中添加 agent 能读取但不会污染数据结构的上下文。而 Markdown 的通用渲染意味着我的声音指南在 Cursor、GitHub 和任何浏览器中看起来都一样。
我的系统使用 11 个 JSONL 文件(posts, contacts, interactions, bookmarks, ideas, metrics, experiences, decisions, failures, engagement, meetings)、6 个 YAML 文件(goals, values, learning, circles, rhythms, heuristics)和 50 多个 Markdown 文件(声音指南、研究、模板、草稿、待办)。每个 JSONL 文件以 schema 行开头:{"_schema": "contact", "_version": "1.0", "_description": "..."}。agent 在读取数据之前就知道结构。
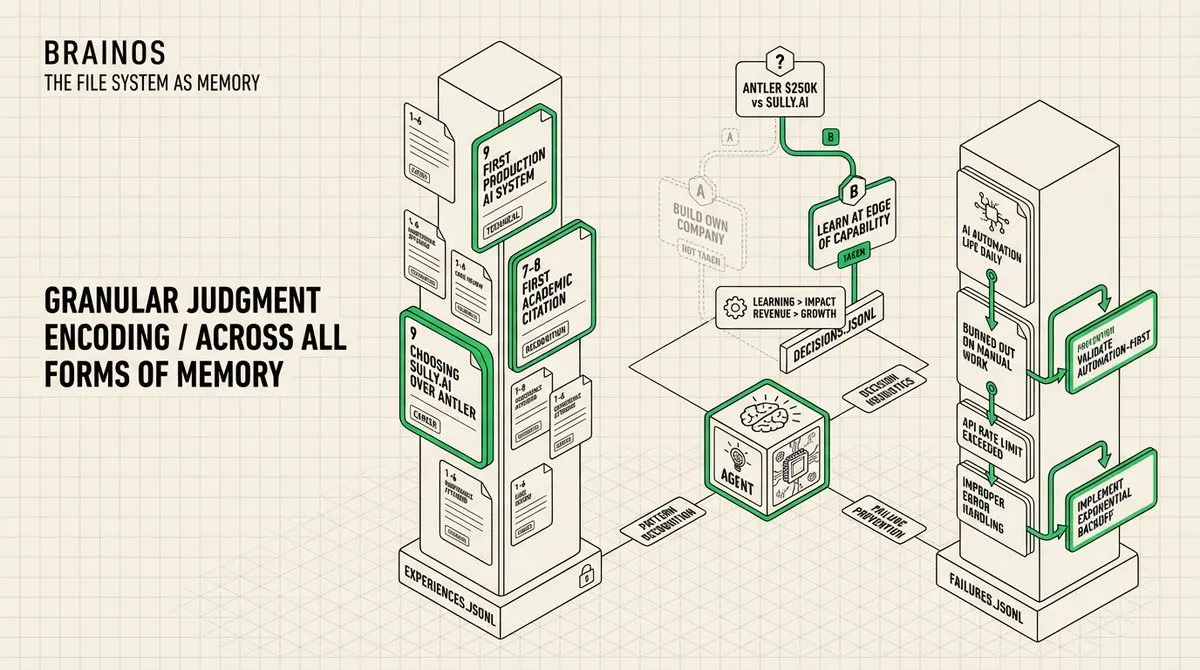
情景记忆(Episodic Memory): 大多数「第二大脑」系统存储事实。我的系统还存储判断。memory/ 模块包含三个 append-only 日志:experiences.jsonl(关键时刻及情感权重分数 1-10)、decisions.jsonl(关键决策及推理、考虑过的替代方案和跟踪的结果)、failures.jsonl(哪里出了错、根本原因和预防措施)。
拥有你的文件的 AI 和拥有你的判断力的 AI 之间存在差异。事实告诉 agent 发生了什么。情景记忆告诉 agent 什么是重要的、我会做什么不同的决定、以及我如何思考权衡。当 agent 遇到类似于我已记录的决策时,它可以参考我过去的推理,而不是生成泛泛的建议。失败日志是最有价值的 – 它编码了需要真实痛苦才能获得的模式识别。
当我在决定是接受 Antler Canada 的 25 万美元投资还是加入 Sully.ai 担任 Context Engineer 时,决策日志捕获了两个选项、每个选项的推理和结果。如果出现类似的职业抉择,agent 不会给我泛泛的职业建议。它会参考我实际思考这些决策的方式:「学习 > 影响力 > 收入 > 增长」是我的优先级顺序,「我能接触所有事情吗?我会在能力边界学习吗?我尊重创始人吗?」是我加入公司的框架。
跨模块引用: 系统使用平面文件关系模型。没有数据库,但结构足以让 agent 跨文件关联数据。interactions.jsonl 中的 contact_id 指向 contacts.jsonl 中的条目。ideas.jsonl 中的 pillar 映射到 identity/brand.md 中定义的内容支柱。书签产出内容创意。帖子指标产出每周回顾。模块在加载时是隔离的,但在推理时是连接的。
没有连接的隔离只是一堆文件夹。跨引用让 agent 在需要时遍历知识图谱。「为我和 Sarah 的会议做准备」触发一个查找链:在联系人中找到 Sarah,拉取她的互动记录,检查涉及她的待办事项,汇编简报。agent 跨模块追踪引用,无需加载整个系统。
我的会前工作流串联三个文件:contacts.jsonl(他们是谁)、interactions.jsonl(按 contact_id 过滤的历史)和 todos.md(任何待处理事项)。agent 生成一页简报,包含关系背景、上次对话摘要和未完成的后续事项。不需要手动组装。数据结构使工作流成为可能。
3) Skill 系统:教会 AI 如何做你的工作
文件存储知识。Skill 编码流程。我按照 Anthropic Agent Skills 标准构建了 Agent Skills – 结构化的指令,告诉 AI 如何执行特定任务,并内置质量关卡。
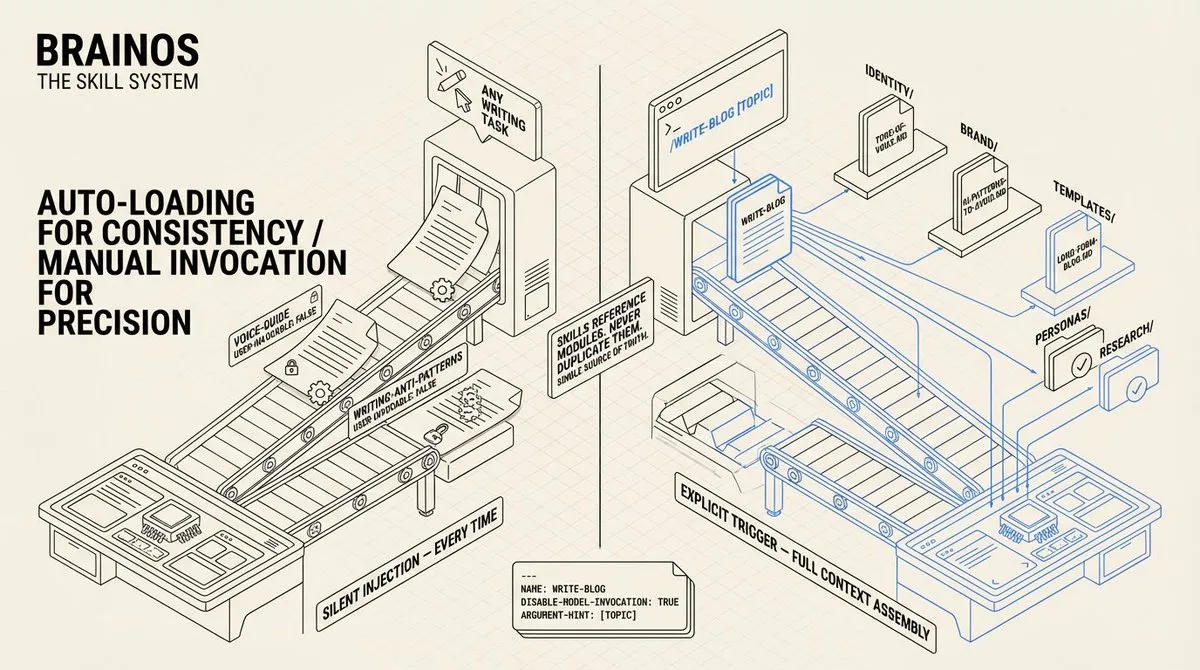
自动加载 vs. 手动调用: 两种类型的 skill 解决两种不同的问题。参考型 skill(voice-guide、writing-anti-patterns)在 YAML frontmatter 中设置 user-invocable: false。agent 读取描述字段,在涉及写作的任务中自动注入它们。我从不调用它们 – 它们每次都静默激活。任务型 skill(/write-blog、/topic-research、/content-workflow)设置 disable-model-invocation: true。agent 无法自行触发它们。我输入斜杠命令,skill 就成为 agent 执行该任务的完整指令集。
自动加载解决了一致性问题。我不必每次要求草稿时都记得说「用我的声音」。系统替我记住了。手动调用解决了精确性问题。研究任务的质量关卡与博客文章不同。将它们分开可以防止 agent 混淆两个不同的工作流。YAML frontmatter 是实现机制,几个元数据字段控制了整个加载行为。
当我输入 /write-blog context engineering for marketing teams 时,五件事自动发生:声音指南加载(我如何写)、反模式列表加载(我绝不怎么写)、博客模板加载(7 节结构及字数目标)、检查人物画像文件夹中的受众画像、检查研究文件夹中的现有主题研究。一个斜杠命令触发完整的上下文组装。skill 文件本身写着「读取 brand/tone-of-voice.md」 – 它引用源模块,从不复制内容。单一真实来源。
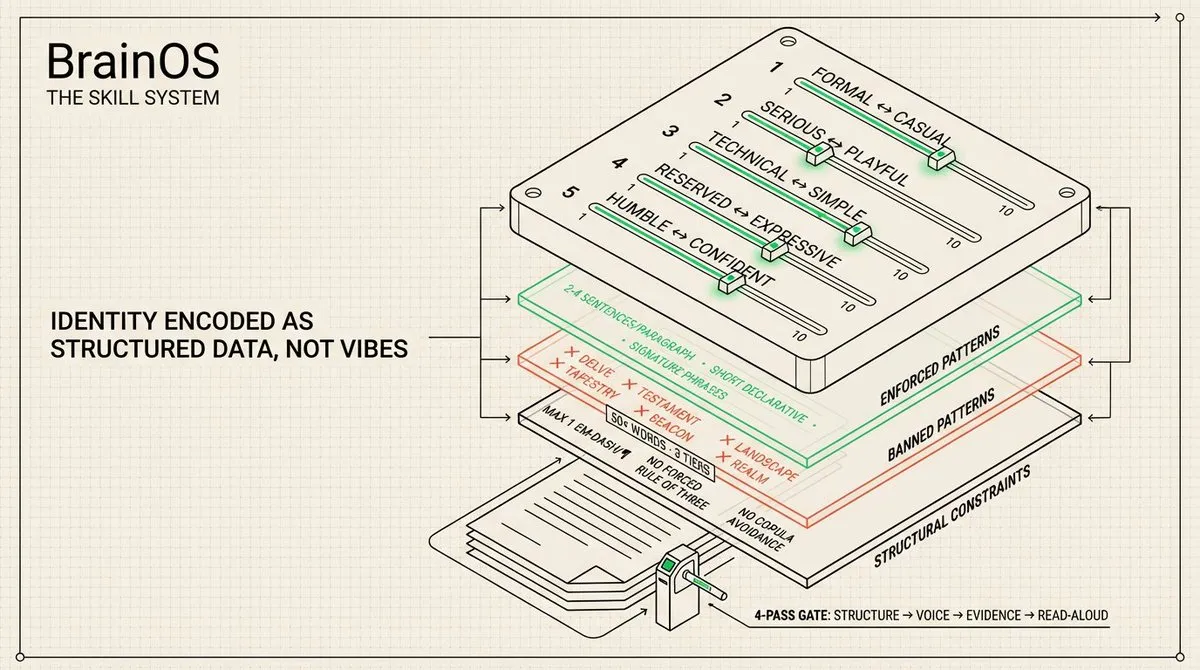
声音系统: 我的声音被编码为结构化数据,外加一些感觉。声音画像对五个属性按 1-10 评分:正式/随意(6)、严肃/有趣(4)、技术/简单(7)、保守/外向(6)、谦逊/自信(7)。反模式文件包含三个等级的 50 多个禁用词、禁用开头、结构性陷阱(强制三段式、系动词回避、过度对冲),以及每段最多一个破折号的硬性限制。
大多数人用形容词描述自己的声音:「专业但亲和」。这对 AI 毫无用处。在技术/简单量表上的 7 分精确告诉模型应该落在哪里。禁用词列表甚至更强大 – 定义「你不是什么」比定义「你是什么」更容易。agent 对照反模式列表检查每份草稿,重写任何触发它的内容。结果是内容听起来像我,因为护栏阻止了它听起来像 AI。
每个内容模板每 500 字包含声音检查点:「我在以洞察引领吗?我用了具体数字吗?我真的会发布这个吗?」博客模板内置了 4 轮编辑流程:结构编辑(钩子是否抓人?)、声音编辑(禁用词扫描、句子节奏检查)、证据编辑(论断有出处吗?),以及朗读测试。质量关卡是 skill 的一部分,不是事后添加的。
模板即结构化脚手架: 五个内容模板定义了不同内容类型的结构。长文博客模板有七个部分(Hook、核心概念、框架、实践应用、失败模式、入门指南、结尾),每部分有字数目标,总计 2,000-3,500 字。推文串模板定义了 11 条的结构,包含钩子、深入分析、结果和 CTA。研究模板有四个阶段:全景扫描、技术深入、证据收集和差距分析。
模板不仅约束创造力,还约束混乱。没有结构,agent 产出无定形的文本团块。有了结构,它产出有节奏、有递进、有收获的内容。每个模板还包含质量检查清单,agent 可以在呈现草稿之前自我评估。
研究模板输出到 knowledge/research/[topic].md,使用结构化格式:执行摘要、全景地图、核心概念、证据库(包含统计数据、引言、案例研究和论文,每项都标注来源和日期)、失败模式、内容机会和按 HIGH/MEDIUM/LOW 评级的来源列表。该研究文档然后输入博客模板的大纲阶段。一个 skill 的输出成为下一个的输入。管道自我构建。
4) 操作系统:我每天实际如何使用
架构没有执行就什么都不是。以下是系统在实践中的运行方式。
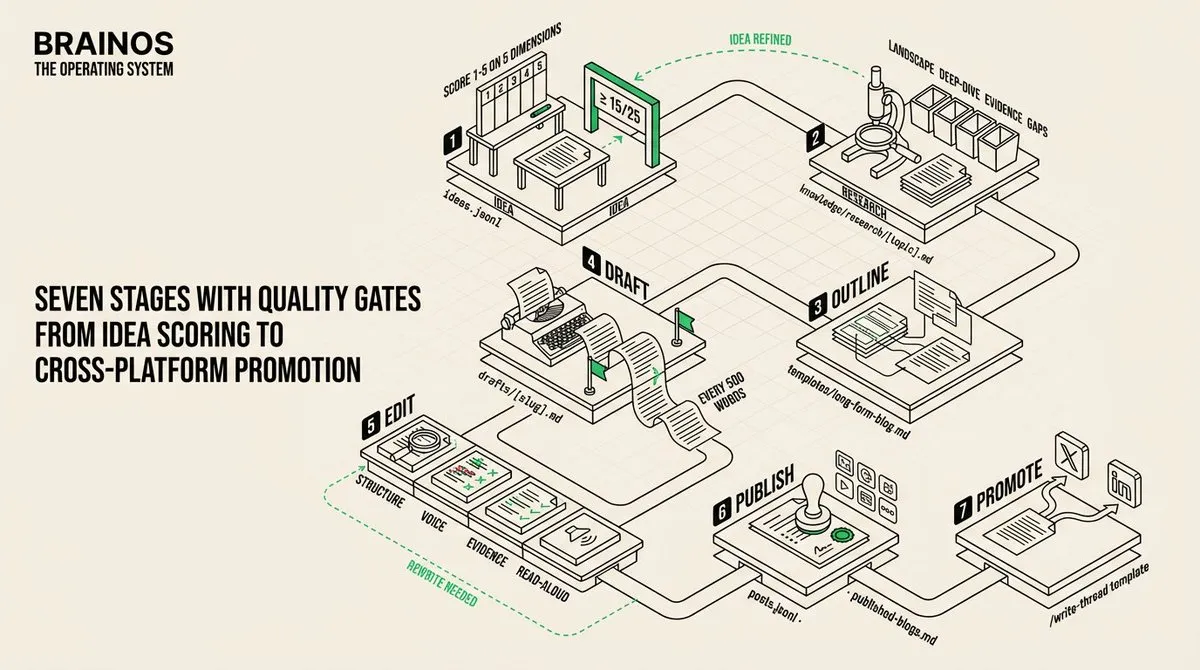
内容管道: 七个阶段:创意、研究、大纲、草稿、编辑、发布、推广。
- 创意被捕获到
ideas.jsonl,带有评分系统 – 每个创意在定位一致性、独特洞察、受众需求、时效性和投入产出比五个维度上按 1-5 评分。总分达到 15 或以上才继续推进。 - 研究输出到知识模块。
- 草稿经过四轮编辑。
- 发布的内容记录到
posts.jsonl,包含平台、URL 和互动数据。 - 推广使用推文串模板创建 X 公告和 LinkedIn 适配版本。
我在周日批量创作内容:3-4 小时,目标产出 3-4 篇文章的草稿和大纲。内容日历将每天映射到一个平台和内容类型。
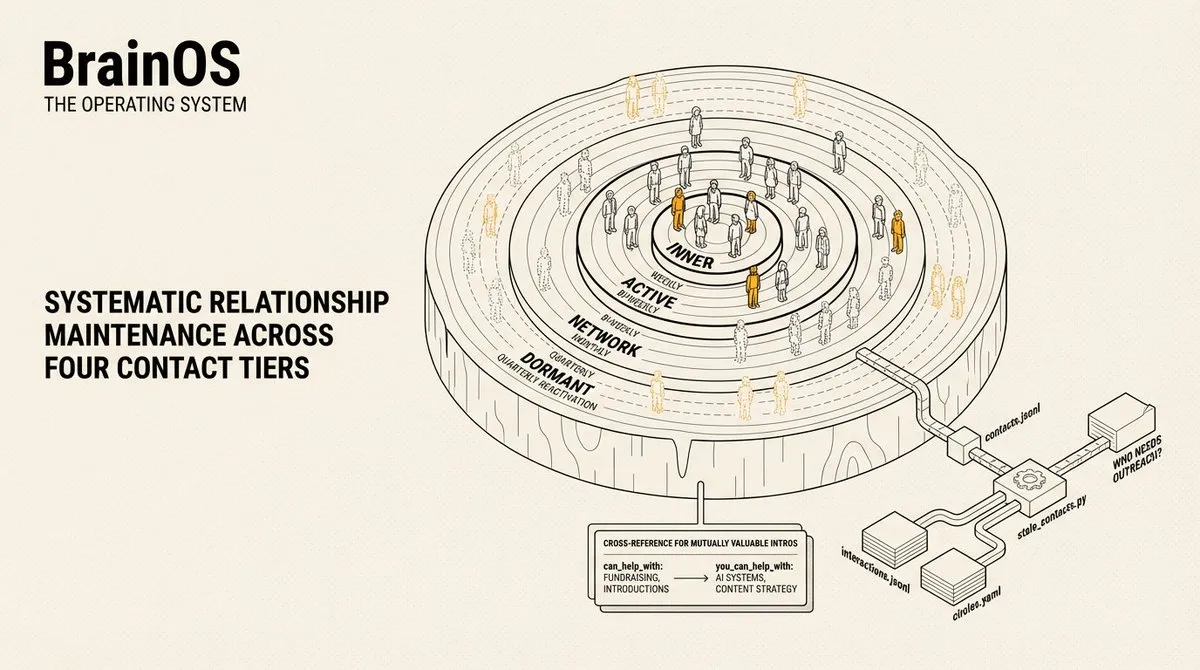
个人 CRM: 联系人按四个圈层组织,维护频率不同:核心圈(每周)、活跃圈(两周)、人脉圈(每月)、沉寂圈(每季度重新激活)。每个联系人记录都有 can_help_with 和 you_can_help_with 字段,启用介绍匹配系统 – 交叉引用这些字段可以发现互惠的引荐机会。互动记录带有情感追踪(positive, neutral, needs_attention),这样关系健康度一目了然。
大多数人把联系人记在脑子里,让关系因疏忽而衰退。stale_contacts 脚本交叉引用联系人(他们是谁)、互动记录(我们上次何时交谈)和圈层(我们应该多久交流一次)来浮现需要联系的人。每周 30 秒的扫描就能显示哪些关系需要关注。
circles.yaml 中的专门分组 – 创始人、投资者、AI 开发者、创作者、导师、学员 – 各有明确的关系发展策略。对于 AI 开发者:分享有用内容、开源协作、提供工具反馈、放大他们的工作。对于导师:带具体问题来、更新先前建议的进展、寻找回馈方式。这些是 agent 在我问「本周应该联系谁?」时遵循的操作指令。
自动化链: 五个脚本处理重复性工作流,它们串联起来实现复合操作。周日周回顾依次运行三个脚本:metrics_snapshot.py 更新数据,stale_contacts.py 标记需关注的关系,weekly_review.py 生成汇总文档,包含完成 vs 计划、指标趋势和下周优先级。内容创意链读取最近的书签、检查未开发的创意、生成新建议,并与内容日历交叉引用以发现排期空白。这些不是 cron 定时任务 – 当我要求回顾时 agent 运行它们,或者我用 npm run weekly-review 触发。
以 agent 可读格式输出到 stdout 的脚本闭合了数据与行动之间的循环。周回顾脚本不仅告诉我发生了什么 – 它参照我的目标,识别哪些关键结果在正轨、哪些落后、下周应该优先什么。脚本从 agent 在正常运行时读取的同一文件中读取,所以没有数据重复或同步问题。
运行周回顾后,agent 拥有了更新下周 todos.md、调整 goals.yaml 进度数字、建议与表现不佳的关键结果对齐的内容主题所需的一切。回顾不是报告 – 它是下周规划的起点。自动化创建了一个反馈循环:目标驱动内容,内容驱动指标,指标驱动回顾,回顾驱动目标。
5) 我犯了什么错,以及我会如何改进
- 第一版过度设计了 schema。我最初的 JSONL schema 每个条目有 15 个以上的字段,大多数是空的。agent 很难处理稀疏数据 – 它们会试图填充字段或评论字段的缺失。我将 schema 精简到 8-10 个核心字段,只在实际有数据时才添加可选字段。更简单的 schema,更好的 agent 行为。
- 声音指南一开始太长了。
tone-of-voice.md的第一版有 1,200 行。agent 开头写得很好,但到第四段就开始偏移,因为声音指令落入了「中间遗忘」区域。我重新组织了结构,将最具辨识度的模式(标志性短语、禁用词、开头模式)放在前 100 行,扩展示例放在后面。关键规则需要在顶部,而不是中间。 - 模块边界比你想象的更重要。我最初将身份和品牌放在一个模块中。当 agent 只需要我的禁用词列表时,它会加载我的整个简历。将它们拆分为两个模块,使仅涉及声音任务的 token 使用量减少了 40%。每个模块边界都是一个加载决策。搞错了就会加载太多或太少。
- Append-only 不可妥协。我早期因为 agent 重写了
posts.jsonl而不是追加,丢失了三个月的帖子互动数据。JSONL 的 append-only 模式不仅仅是一个约定 – 它是一个安全机制。agent 可以添加数据,不能销毁数据。这是系统中最重要的架构决策。
6) 结果与背后的原则
真正的结果比任何指标都简单。我打开 Cursor 或 Claude Code,开始对话,AI 已经知道我是谁、我如何写作、我在做什么、我关心什么。它用我的声音写作,因为我的声音被编码为结构化数据。它遵循我的优先级,因为我的目标在一个 YAML 文件中,它在建议我做什么之前就会读取。它管理我的关系,因为我的联系人和互动记录在它可以查询的文件中。
所有这一切背后的原则:这是 Context Engineering(上下文工程),而非 Prompt Engineering(提示词工程)。Prompt engineering 问的是「我如何更好地措辞这个问题?」Context engineering 问的是「这个 AI 需要什么信息才能做出正确的决策,以及我如何结构化这些信息使模型真正使用它?」
这个转变是从优化单次交互到设计信息架构。这就像写一封好邮件和建立一个好的归档系统之间的区别。一个帮你一次,另一个每次都帮你。
整个系统装在一个 Git 仓库里。克隆到任何机器,将任何 AI 工具指向它,操作系统就在运行。零依赖,完全可移植。而因为它是 Git,每个改动都有版本记录,每个决策都可追溯,没有什么会真正丢失。
作者:Muratcan Koylan – Sully.ai 的 Context Engineer,为医疗 AI 设计上下文工程系统。他在上下文工程方面的开源工作(GitHub 8,000+ Star)被学术研究与 Anthropic 并列引用。此前任 99Ravens AI 的 AI Agent 系统经理,构建处理每周 10,000+ 次交互的多 agent 系统。
如果这篇文章对你有帮助,欢迎请我喝杯咖啡,支持我继续创作更多内容。
Buy me a coffee