Google 打造 Gemini 3 不是为了聊天——而是为了 World Model
出处: 本文转载自 SETI Park (@seti_park) 发布的 X Article,原文发布于 2026 年 2 月 22 日。
关于作者: SETI Park 是一位韩国专利分析师(Patent Analyst),专注于解读 Tesla、NVIDIA、Google/DeepMind、SpaceX、Anthropic 等科技巨头的专利,擅长从专利文件中提炼技术战略洞察。他在 X 上拥有超过 16,000 名关注者,同时运营 YouTube 频道。
TLDR: Google 的专利 US20260030905A1 揭示了 Gemini 3 视觉能力背后的真正目的——不是为了聊天,而是为了构建 World Model。该专利描述了一个 ConGen-Feedback 系统,能够检测图像与文本之间的四类不匹配(物体、属性、动作、空间关系),通过迭代自我纠正循环不断改进,并大规模制造训练数据。这四个维度恰好是模拟物理现实所需的核心能力,而 Gemini 3 的基准测试成绩完美映射了这四个维度。从 2023 年的 SeeTRUE 论文到 2026 年的 Waymo World Model,Google 一直在沿着同一条路线图前进。

2 月 6 日,Waymo 发布了 Waymo World Model——一个基于 Google DeepMind 的 Genie 3 构建的自动驾驶仿真引擎。它能生成车队从未遇到过的驾驶场景:龙卷风、被淹没的十字路口、路上的大象。博客文章中写道:“Genie 3 从多样化视频预训练中获得的强大世界知识,使我们的车辆能够探索车队从未直接观察到的场景。”
这句话——来自视频预训练的世界知识——引向了一个科技媒体大多忽略的问题:
为什么 Google 在组合式视觉(compositional vision)上投入如此之大——不是那种仅仅"看到"图像的能力,而是能理解物体、属性、动作和空间关系的能力?
数字讲述了部分故事。Google 为 Gemini 3 Pro 发布的基准测试表涵盖了七个视觉类别的 25 项以上评估,在每一项上都领先。但基准测试是输出结果,它们告诉你模型能做什么,却不告诉你为什么要这样构建。
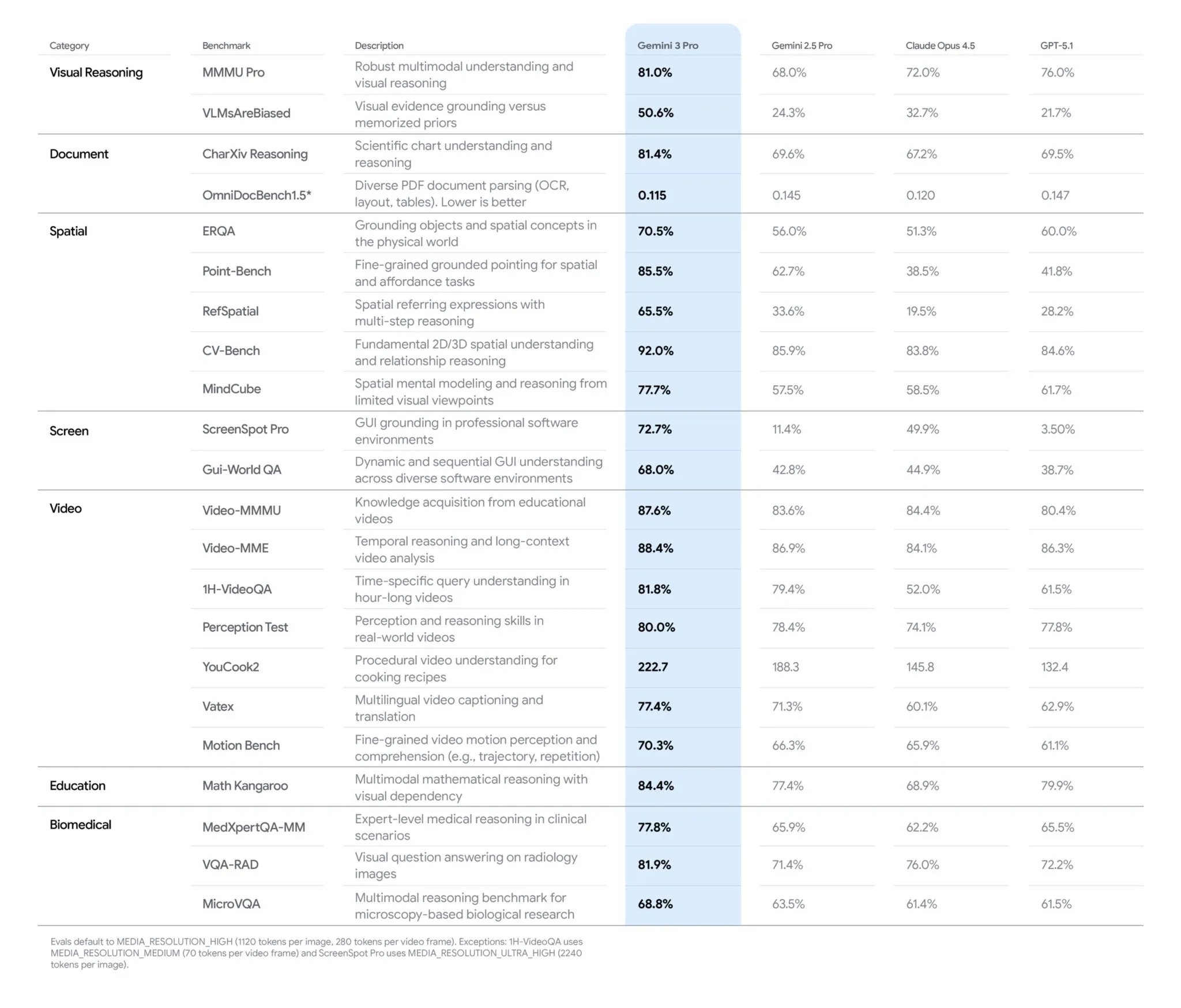
看看 Google 选择测量什么。“空间”(Spatial)是一个独立类别,配有五个专属基准测试。“屏幕”(Screen)有三个。这些不是泛泛的准确率测试,而是在衡量物理世界模型所需的特定能力。
一项专利——US20260030905A1,2024 年 5 月提交,2026 年 1 月 29 日公开——揭示这条路线图是架构性的,而非渐进式的。
一个不只是给图文匹配度打分的系统。它能解释不匹配发生在哪里以及为什么,通过迭代修正,并大规模生成每种不匹配类型的训练数据。
核心论点:Gemini 3 在组合式视觉上的强大表现,源于一个递归自我纠正引擎——设计目标不是聊天,而是构建 World Model。
不是分数,而是解释
现有指标如 CLIPScore 只产生一个数字。0.7 意味着"大概匹配"。但它们从不告诉你不匹配出现在哪里,或者为什么。专利的表述很直白:基于嵌入的模型如 CLIP"在需要细粒度组合式理解的任务上经常表现不佳"(“often struggle with tasks requiring fine-grained compositional understanding”)[0005]。文本相似度指标"只评估文本相似性,忽略了视觉信息和更深层的语义联系"(“only assess textual similarity, ignoring visual information and deeper semantic connections”)[0035]。
该专利提出了 ConGen-Feedback:一个同时输出文本解释和边界框标注的系统,指出哪里出了问题。
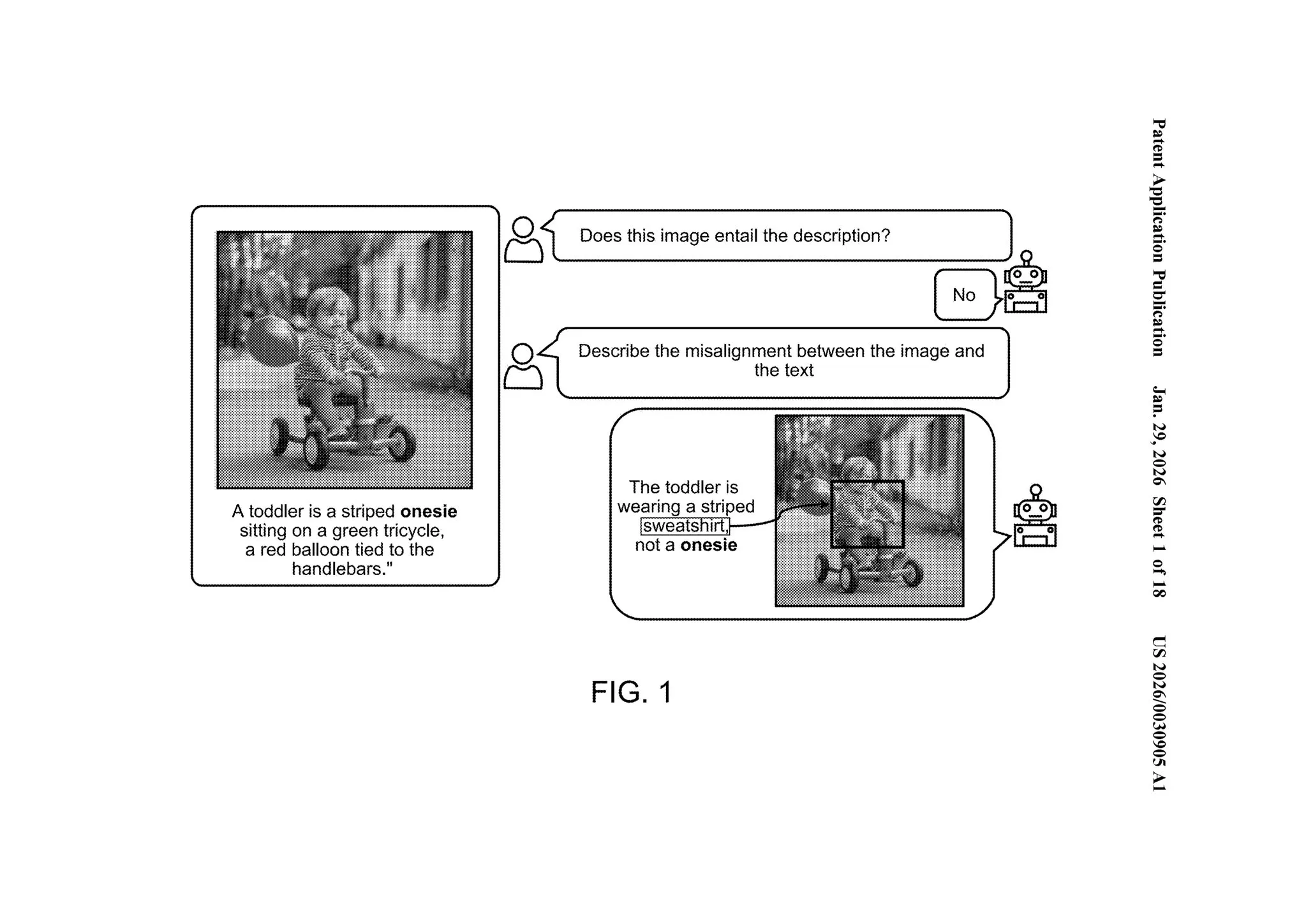
图 1 具象化了这个过程。文本描述"一个穿着条纹连体衣的幼儿坐在绿色三轮车上"。图像显示同一个幼儿穿着条纹卫衣。系统检测到这一差异,生成文本解释,并在衣服周围绘制边界框 [0066]。
一个模型,两种输出:什么出了问题(文本)和问题在哪里(视觉)。
“通过使用单一机器学习模型同时生成不匹配的文本描述和视觉描述,系统避免了计算的重复……提高了内存使用效率并降低了推理时间。"——[0061]
学术基础——由同一个 Google Research Israel 团队撰写的 SeeTRUE 论文(NeurIPS 2023)指出,这类模型可用于"过滤训练数据以提升文本到图像模型的训练效果”。
这不是一个评估工具,而是让视觉模型从自身错误中学习的基础设施。
纠正循环
检测过程会反复进行。系统生成文本诊断,然后将其传入第二个模型来修改图像(或文本)。修改后的输出再次进入同一检测系统。
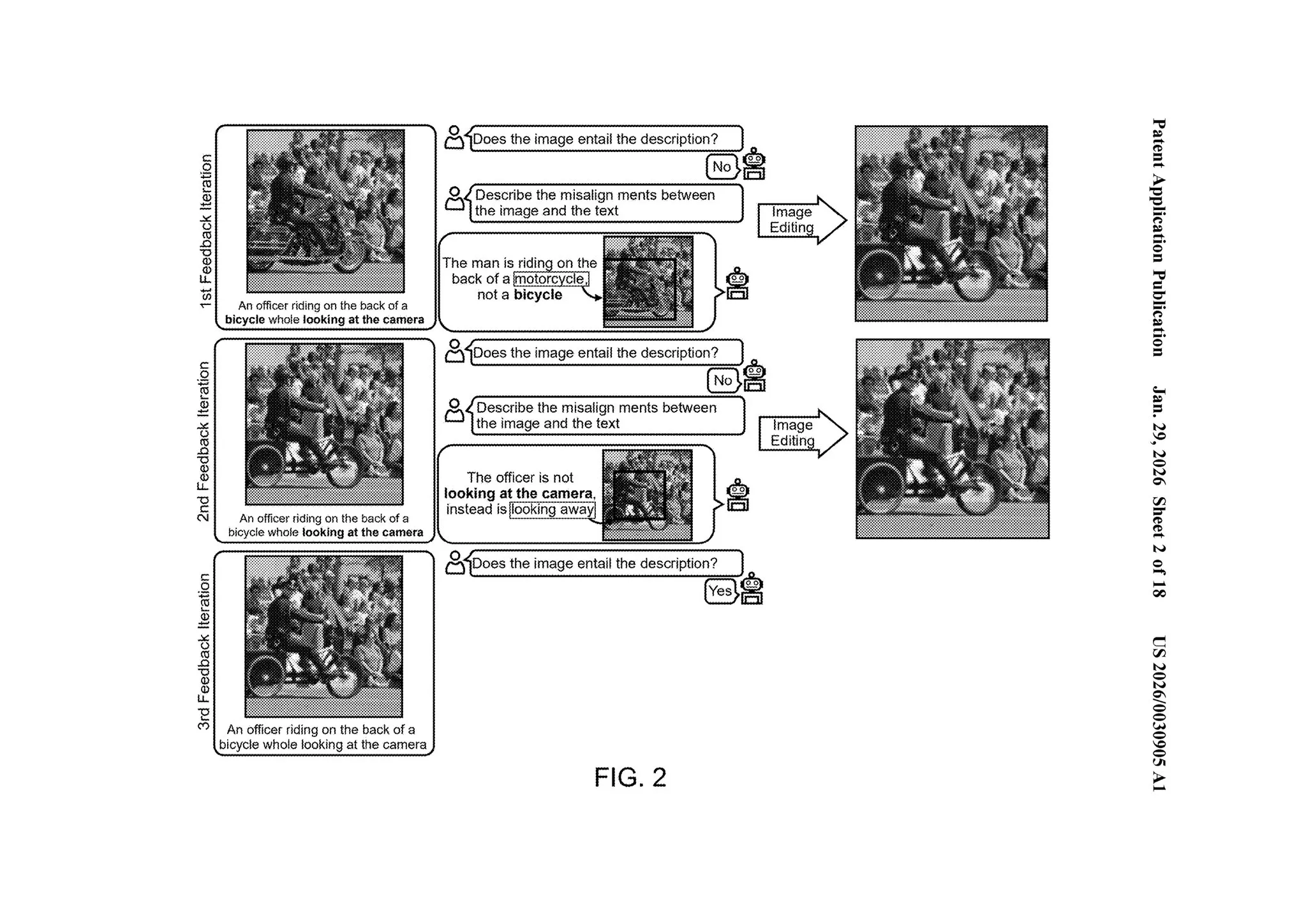
图 2 展示了完整循环。
文本:“一名警官骑在自行车后座上,望向镜头。”
迭代 1。 “不对。该男子骑的是摩托车后座,不是自行车。“边界框标在摩托车上。图像被重新生成为自行车。
迭代 2。 “不对。警官没有望向镜头,而是看向别处。“边界框标在面部。图像被重新生成为警官面向镜头。
迭代 3。 “正确。“图像现在与描述匹配。
专利描述了处理多个同时存在的差异:“源文本可能描述的是一栋蓝色房子,但生成的图像中可能是一栋红色房子。或者源文本描述了一个有猫的场景,但生成的图像中却出现了一条狗。"(“the source text string might describe an image having a blue house, but the generated image may include a red house. Or a source text string may describe a scene involving a cat, but the generated image may include a dog instead.")[0004]
这是一个迭代式的奖励与纠正循环。模型不只是识别失败模式,它修复问题并重新检查。每个循环都在为训练数据添砖加瓦。
四种不匹配 = 物理现实的语法
不匹配的分类体系并非随意设定。专利定义了四个类别 [0045]:
物体(Object)。 “猫"对"狗”。场景正确,实体错误。
属性(Attribute)。 “蓝色的猫"对"白色的猫”。物体正确,属性错误。
动作(Action)。 “跳跃"对"站立”。物体和属性正确,行为错误。
空间关系(Spatial Relation)。 “跳过栅栏"对"在栅栏旁边跳”。一切正确,唯独相对位置错误。
这四个维度——存在什么、看起来像什么、在做什么、在哪里——恰恰是 World Model 模拟物理现实所需的核心能力。而 Google 的基准测试套件直接映射了这四个维度。
MMMU-Pro(81%)测试模型能否在复杂视觉场景中推理物体的属性和关系。Video-MMMU(87.6%)测试模型能否追踪动作和状态随时间的变化。空间类别深入到五个基准测试,精确对应专利第四种不匹配类型的要求:RefSpatial 衡量多步空间推理能力(65.5%,几乎是 Gemini 2.5 Pro 的 33.6% 的两倍)。MindCube 衡量从有限视角进行空间心智建模的能力(77.7% 对 GPT-5.1 的 61.7%)。
专利训练模型检测四种物理不匹配。Google 构建了一套基准测试来精确衡量这四个维度。结果不言自明。
训练数据工厂
该专利通过 TV-Feedback 流水线大规模制造这些不匹配。对于每一对匹配的图文组合,它在所有四个类别上生成负样本。一个正向描述如"一只猫躺在蓝色垫子上"会产生变体:“一只狗躺在蓝色垫子上”(物体)、“一只猫躺在红色垫子上”(属性)、“一只猫坐在蓝色垫子上”(动作)、“一只猫躺在蓝色垫子下面”(空间)。
一个 NLI 模型负责质量过滤:保留矛盾正确率(CC)高于 0.25 的样本,以及达到最低蕴含精度的样本。系统只保留那些足够困难、具有训练价值的不匹配。

图 3 展示了成果:来自六个数据集(PickaPic、ImageReward、COCO、Flickr30k、DOCCI、SVO-Probes)的训练对,每种不匹配类型都配有解释和边界框。
一座无限规模地生产物理现实"错误版本"的工厂,并教会模型检测和纠正这些错误。
该专利还引入了 VQ²,一种将对齐度分解为原子化问答对的评分方法。系统不再给出单一分数,而是生成 10-20 个关于图像特定方面的二元问题(“有没有猫?"、“垫子是蓝色的吗?"、“猫是躺着的吗?"),减少幻觉并实现细粒度调试。
专利明确点名了目标模型:“示例 VLM 包括 PaLI 和 Gemini 模型家族”(“Example VLMs include the PaLI and Gemini model families”)[0036]。不是某个特定版本,而是整个模型家族。
时间线
2023 年。 SeeTRUE(NeurIPS 2023)由 Google Research Israel 团队建立图文对齐评估体系。
2024 年。 同一团队发表 ConGen-Feedback(ECCV 2024),提出递归自我纠正系统。Google 提交专利(优先权日 2024 年 5 月 17 日),涵盖检测系统、合成数据流水线、迭代纠正循环和 VQ² 评分方法。
2025 年 5 月。 在 Google I/O 上,Demis Hassabis 宣布:“我们正在将 Gemini 扩展为一个 World Model,能够制定计划并通过模拟世界的各个方面来想象新的体验。”
2025 年 8 月。 Genie 3 发布。DeepMind 称其为"World Model 的新前沿”。研究人员表示:“我们认为 World Model 是通往 AGI 的关键,尤其是对于具身智能体。”
2025 年 11 月。 Gemini 3 Pro 亮相。Google 发布了一份涵盖七个视觉类别、25 项以上评估的基准测试表,全部领先。与竞争对手差距最大的出现在空间和屏幕类别——最依赖组合式推理的两个类别。
2026 年 1 月。 Google 在 Gemini 3 Flash 中推出 Agentic Vision:一个"思考-行动-观察”(Think-Act-Observe)循环,模型先规划视觉分析策略,操控图像(缩放、裁剪、增强),然后重新检查结果。这种"检测 → 操控 → 再检测"的结构与专利的迭代纠正循环如出一辙。同月,专利正式公开。
2026 年 2 月。 Waymo World Model 基于 Genie 3 发布,将 2D 视频理解转化为多传感器 3D 输出,用于自动驾驶仿真。该系统生成"车队从未直接观察到的场景”。
专利揭示了什么
每家 AI 公司都在提升视觉准确度。但这项专利揭示了不同的东西:递归自我改进的基础设施。一个能检测不匹配发生在哪里以及为什么的系统,能在物理理解的四个维度上生成无限量的训练数据,然后通过迭代纠正反哺更强的模型。
Gemini 3 在组合式视觉上的优势不是终点,而是通往更远目标的一个检查站——能够建模、预测和模拟物理世界的 AI。
专利痕迹表明,这从一开始就是计划的一部分。
Sources
- US 2026/0030905 A1, “Vision-Language-Model-Based System for Assessing the Consistency Between Images and Textual Descriptions,” filed May 2024, published January 29, 2026
- Yarom et al., “What You See is What You Read? Improving Text-Image Alignment Evaluation,” NeurIPS 2023
- Bitan et al., “Mismatch Quest: Visual and Textual Feedback for Image-Text Misalignment,” ECCV 2024
- Google, “Gemini 3 Pro: the frontier of vision AI,” Google Blog, 2025
- Hassabis, “Google I/O 2025: Gemini as a universal AI assistant,” Google Blog, May 20, 2025
- Google DeepMind, “Genie 3: A new frontier for world models,” August 5, 2025
- Waymo Blog, “The Waymo World Model,” February 6, 2026
如果这篇文章对你有帮助,欢迎请我喝杯咖啡,支持我继续创作更多内容。
Buy me a coffee