LLM 推理提速全解析:GPT-5.3-Codex 与 Claude Fast Mode 背后的四层加速
TL;DR: OpenAI 和 Anthropic 最近都在推理速度上取得了显著进展。GPT-5.3-Codex 快了约 25%,Claude Opus 4.6 的 Fast Mode 输出速度提升最高 2.5 倍。两家的技术路径本质一致:通过算法(Speculative Decoding)、内核(FlashAttention)、服务层(vLLM/Continuous Batching)和模型架构(MoE/量化)四层协同实现加速。本文拆解这四层机制,并附 10 篇核心论文。

为什么 LLM 突然变快了
如果你最近频繁使用 Claude 或 GPT,可能已经注意到:响应速度明显变快了。
这不是错觉。2026 年初,两大模型厂商几乎同时交出了速度成绩单:
- OpenAI: GPT-5.3-Codex 比前代快约 25%
- Anthropic: Claude Opus 4.6 推出 Fast Mode,输出 token 速率(OTPS)提升最高 2.5 倍
有意思的是,两家走的不是同一条产品路线,但底层技术逻辑高度一致。
OpenAI 的做法:基础设施 + 推理栈优化
OpenAI 在 GPT-5.3-Codex 的发布页中直接给出了数字:
“…which is also 25% faster.” – OpenAI - Introducing GPT-5.3-Codex
提速归因于:
“…thanks to improvements in our infrastructure and inference stack…”
这句话说得克制。OpenAI 没有透露具体用了哪些优化技术——是 Speculative Decoding 的某个变体,还是内核层的改进,还是服务层的调度升级,官方没有公开细节。
从 System Card 来看,这次提速更像是一次全栈工程优化,而非单一算法突破。
Anthropic 的做法:同一模型,不同推理配置
Anthropic 的策略更透明一些。Fast Mode 不是一个新模型,而是 Opus 4.6 的加速推理配置:
“Fast mode runs the same model with a faster inference configuration.” – Anthropic Docs - Fast mode
关键点:
“There is no change to intelligence or capabilities.”
也就是说,模型权重不变,能力不变,只是推理过程跑得更快。官方数据是输出 token 速率提升最高 2.5 倍。
这里有个细节值得注意:Fast Mode 主要优化的是输出阶段(OTPS),而非首 token 时间(TTFT)。对于长输出任务(写代码、写文章),提速感知会更明显;对于短回复,差异可能不大。
四层提速原理
抽象来看,LLM 推理的延迟可以拆解为三个指标:
| 指标 | 含义 | 谁在乎 |
|---|---|---|
| TTFT | 首 token 时间 | 对话体验,用户等待感 |
| OTPS | 输出 token 速率 | 长输出任务的实际吞吐 |
| E2E | 端到端时长 | Agent 场景的整体效率 |
要让这三个指标同时变好,需要在四个层面协同优化。
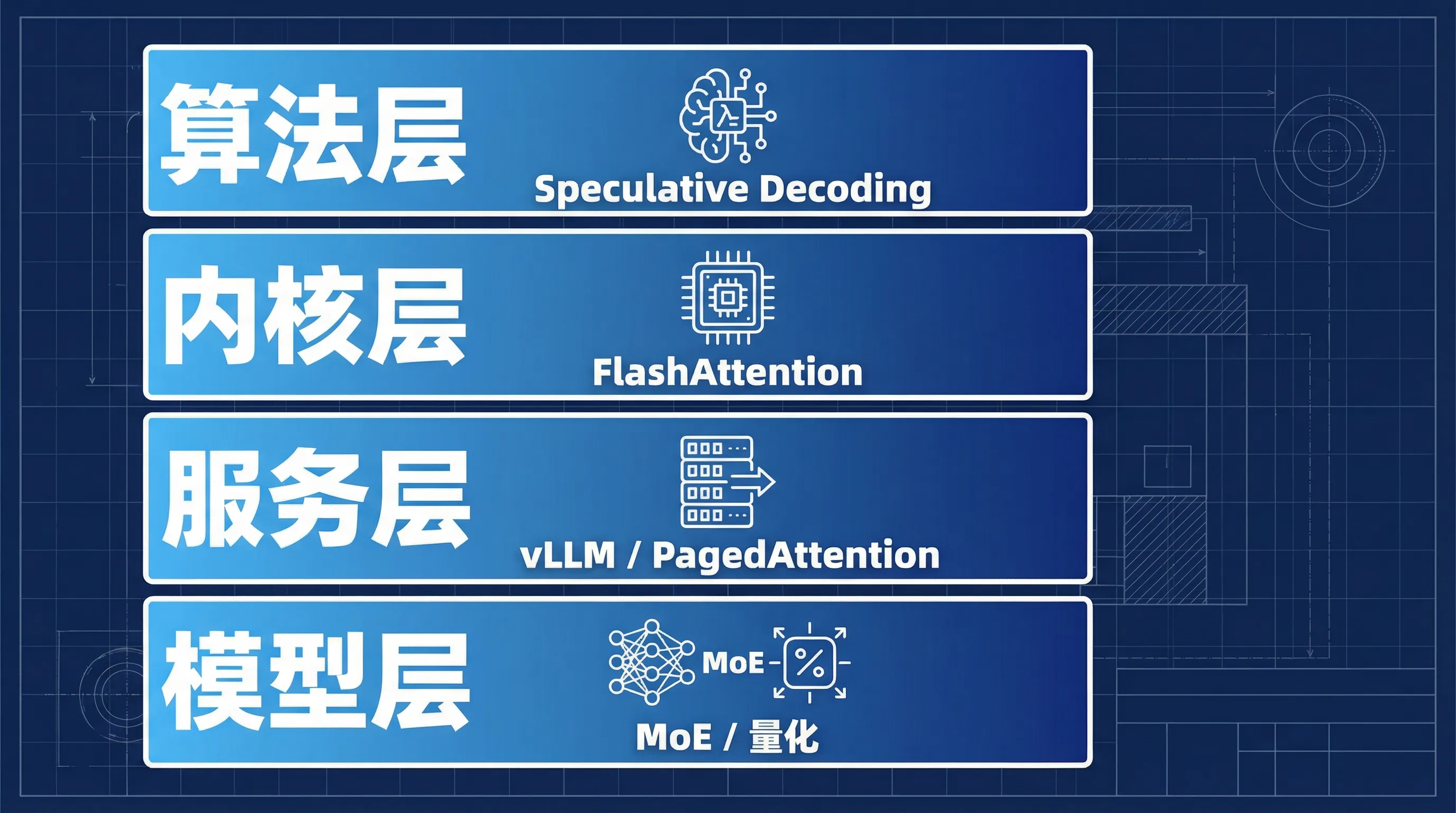
第一层:算法 – Speculative Decoding
这是最优雅的一层优化。
传统 LLM 生成是严格串行的:生成一个 token,才能生成下一个。大模型每生成一个 token 都要跑一次完整的前向传播,开销巨大。
Speculative Decoding 的思路是:用一个小模型先快速草拟多个 token,再让大模型一次性校验。如果小模型猜对了(在很多场景下准确率很高),大模型只需要一次前向传播就验证了多个 token,等效于跳过了多个串行步骤。
这个方法的精妙之处在于:输出质量完全不变。校验失败的 token 会被丢弃并重新生成,数学上等价于大模型自己逐个生成。

后续的 Medusa 和 EAGLE 系列进一步改进了草拟策略——用多头并行草拟提高接受率,用动态草拟树适应不同上下文,把加速比推得更高。
第二层:内核 – FlashAttention
Attention 计算是 Transformer 的核心,也是最大的性能瓶颈之一。
传统实现中,attention 的中间结果需要反复在 GPU 的高速计算单元(SRAM)和大容量显存(HBM)之间搬运。HBM 的带宽远低于计算速度,形成了严重的 IO 瓶颈。
FlashAttention 的解法是:重新组织计算顺序,让 attention 尽可能在 SRAM 内完成,减少 HBM 往返次数。这是一个纯工程优化——算法逻辑不变,结果精确一致,但速度大幅提升。
FlashAttention-2 进一步优化了并行划分策略,在长序列场景下效果更显著。
第三层:服务 – vLLM 与 Continuous Batching
前两层解决的是「单次推理怎么更快」,这一层解决的是「同时服务一万个用户怎么更快」。
核心问题是 KV Cache 管理。每个用户的对话都需要维护一份 KV Cache(键值缓存),长对话的 KV Cache 可以占用数 GB 显存。传统做法是预分配固定大小的显存块,浪费严重。
vLLM 引入了 PagedAttention:像操作系统管理内存一样管理 KV Cache,按需分页、动态回收。这把显存利用率提升了数倍,直接转化为更高的并发能力。
另一个关键技术是 Continuous Batching(连续批处理)。传统批处理要等一批请求全部完成才开始下一批;Continuous Batching 允许请求随时加入和退出批次,大幅减少 GPU 空转时间。
第四层:模型架构 – MoE 与量化
最后一层是在模型本身上做文章。
MoE(Mixture of Experts) 的核心思想是:模型有很多「专家」子网络,但每次只激活其中少数几个。总参数量可以很大(保证能力),但每个 token 的实际计算量远小于全参数模型。Switch Transformer 是这条路线的代表。
量化(如 AWQ)则是用更低精度的数值(比如 4-bit 代替 16-bit)来存储模型权重。这直接减少了显存占用和带宽需求,代价是极小的精度损失——在多数任务上几乎感知不到。
这对开发者意味着什么
四层加速不是学术概念,它们已经在生产环境中落地,直接影响你的使用体验:
Agent 场景受益最大。Agent 需要多轮调用 LLM,每次调用的延迟降低都会累积。一个 10 步的 Agent 工作流,每步快 2 倍,整体就快了 20 倍。
Fast Mode / 高速模式将成为标配。当推理加速能做到「能力不变、速度翻倍」,没有理由不默认开启。预计更多厂商会跟进类似产品。
成本与速度在收敛。更快的推理 = 更短的 GPU 占用时间 = 更低的成本。这四层优化中的每一层都同时降低了延迟和成本。
选型时关注 OTPS 而非只看基准分数。模型能力相近时,推理速度将成为关键的差异化指标。
延伸阅读
以下是支撑本文技术分析的核心论文,按层分类:
算法层 – Speculative Decoding 系列
- Leviathan et al. – Fast Inference from Transformers via Speculative Decoding (ICML 2023)
- Cai et al. – Medusa: Simple LLM Inference Acceleration (2024)
- Li et al. – EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty (2024)
- Li et al. – EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees (2024)
内核层 – FlashAttention 系列
- Dao et al. – FlashAttention: Fast and Memory-Efficient Exact Attention (NeurIPS 2022)
- Dao – FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning (2023)
服务层 – 推理系统
- Kwon et al. – Efficient Memory Management for Large Language Model Serving with PagedAttention (SOSP 2023)
- Yu et al. – Orca: A Distributed Serving System for Transformer-Based Generative Models (OSDI 2022)
模型层 – 架构与量化
- Lin et al. – AWQ: Activation-aware Weight Quantization (MLSys 2024)
- Fedus et al. – Switch Transformers: Scaling to Trillion Parameter Models (2021)
如果这篇文章对你有帮助,欢迎请我喝杯咖啡,支持我继续创作更多内容。
Buy me a coffee